10 Summary measures
![]()
![]()
10.1 Overview
As you learned in Chapter 3, quantitative data analysis can be conceived as three activities: summarising, visualising and modelling data. In this chapter, you will learn about summarising data. When we say “summarising data” we usually mean summarising data variables, by themselves or in group. We can summarise statistical variables using summary measures. There are two types of summary measures.
Measures of central tendency indicate the typical or central value of a variable.
Measures of dispersion indicate the spread or dispersion of the variable values around the central tendency value.
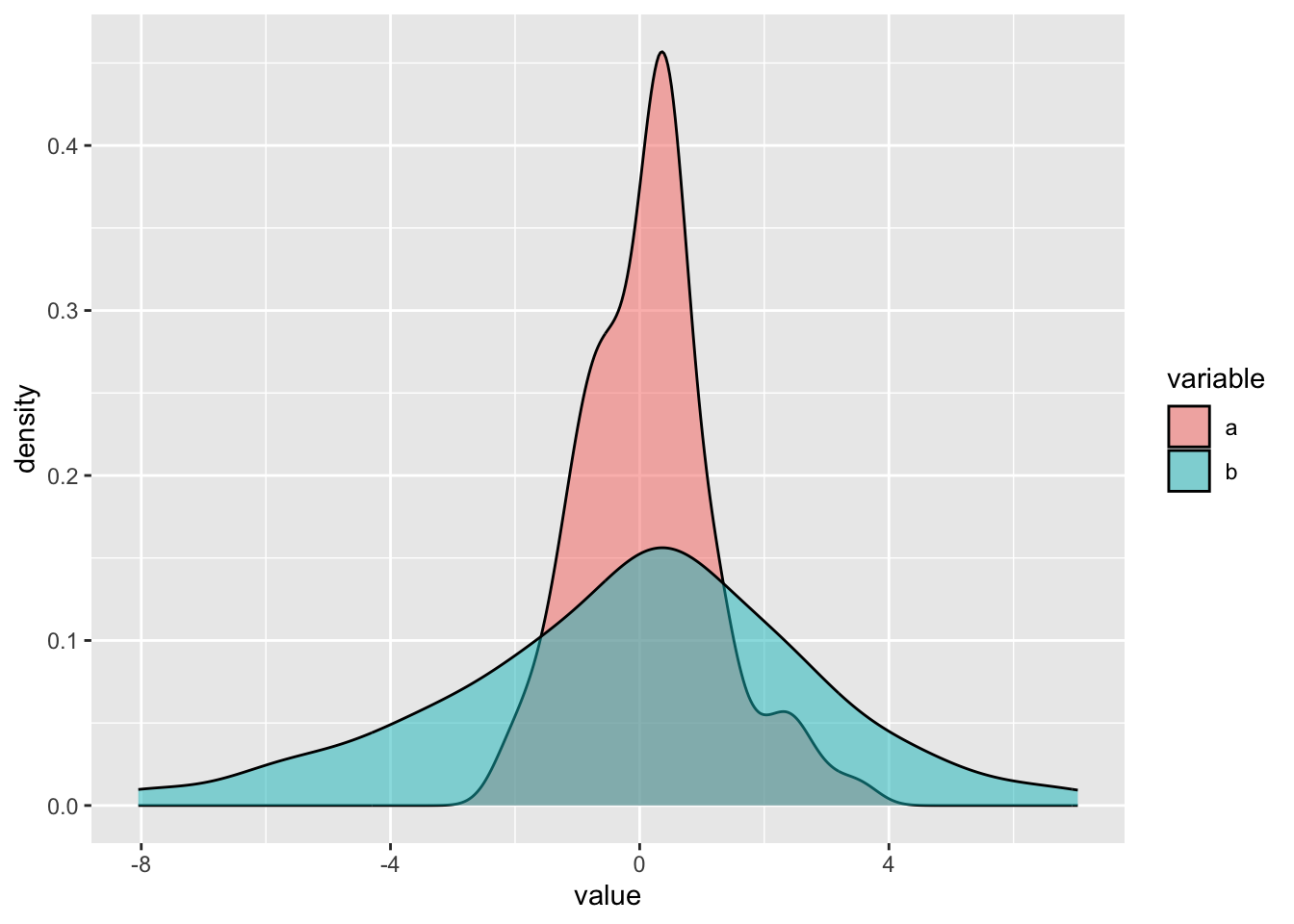
Always report a measure of central tendency together with its measure of dispersion! A central tendency measure captures only one aspect of the “distribution” of the values and variables with the same central tendency value could have very different dispersion, and hence be very different in nature. For example, look at the density plot in Figure 10.1 (you will learn more about them in Chapter 18). These plots are good at showing the distribution of values of numeric variables. The higher the density the curve, the more the values under that part of the curve are represented in the sample. Variable a and b have the same mean (central tendency): the mean is 0. But a has a standard deviation (measure of dispersion, more on this below) of 1 while b’s standard deviation is 3. You can appreciate how different a and b are, despite having exactly the same mean. This should show how important it is to not only report (and think about) central tendencies, like the mean, but also the dispersion of the data around the central tendency.
The following call-outs list common measures of central tendency and dispersions and how they are calculated. You will probably be familiar with most of them and you don’t have to memorise the formulae. The sections after this one will dive into when to use each measure (and how to get them in R), which is much more important.
10.2 Measures of central tendency
A measure of central tendency approximately tells you where the data is most concentrated. There are three common measures of central tendency: mean, median and mode.
10.2.1 Mean
Use the mean with numeric continuous variables, if:
- The variable can take on any positive and negative number, including 0.
mean(c(-1.12, 0.95, 0.41, -2.1, 0.09))[1] -0.354- The variable can take on any positive number only.
mean(c(0.32, 2.58, 1.5, 0.12, 1.09))[1] 1.12210.2.2 Median
Use the median with numeric (continuous and discrete) variables.
# odd N
median(c(-1.12, 0.95, 0.41, -2.1, 0.09))[1] 0.09# even N
even <- c(4, 6, 3, 9, 7, 15)
median(even)[1] 6.5# the median is the mean of the two "central" number
sort(even)[1] 3 4 6 7 9 15mean(c(6, 7))[1] 6.510.2.3 Mode
Use the mode with categorical (discrete) variables. Unfortunately the mode() function in R is not the statistical mode, but rather it returns the R object type.
You can use the table() function to “table” out the number of occurrences of elements in a vector.
table(c("red", "red", "blue", "yellow", "blue", "green", "red", "yellow"))
blue green red yellow
2 1 3 2 The mode is the most frequent value: here it is red, with 3 occurrences.
10.3 Measures of dispersion
A measure of dispersion measures how much spread the data is around the measure of central tendency.
10.3.1 Minimum and maximum
You can report minimum and maximum values for any numeric variable.
x_1 <- c(-1.12, 0.95, 0.41, -2.1, 0.09)
min(x_1)[1] -2.1max(x_1)[1] 0.95range(x_1)[1] -2.10 0.95Note that the range() function does not return the statistical range (see next section), but simply prints both the minimum and the maximum.
10.3.2 Range
Use the range with any numeric variable.
x_1 <- c(-1.12, 0.95, 0.41, -2.1, 0.09)
max(x_1) - min(x_1)[1] 3.05x_2 <- c(0.32, 2.58, 1.5, 0.12, 1.09)
max(x_2) - min(x_2)[1] 2.46x_3 <- c(4, 6, 3, 9, 7, 15)
max(x_3) - min(x_3)[1] 1210.3.3 Standard deviation
Use the standard deviation with numeric continuous variables, if:
- The variable can take on any positive and negative number, including 0.
sd(c(-1.12, 0.95, 0.41, -2.1, 0.09))[1] 1.23658- The variable can take on any positive number only.
sd(c(0.32, 2.58, 1.5, 0.12, 1.09))[1] 0.989555510.4 Summary table of summary measures
To conclude, here is a table that summarises when each measure should be used, depending on the nature of the variable. You can use this table as a cheat-sheet. Green cells indicate that the measure is appropriate for the variable, red cells indicates that they are not and should not be used, and orange cells indicate you should exercise caution when using those measures with those variables. Gray cells indicate that it’s mathematically impossible to apply that measure to that type of variable.
