polite <- read_csv("data/winter2012/polite.csv")34 Regression models: interactions using indexing
![]()
![]()
f0_bm_int2 <- brm(
f0mn ~ 0 + gender:attitude,
family = gaussian,
data = polite,
cores = 4,
seed = 7123,
file = "cache/ch-regression-interaction-index_f0_bm_int2"
)summary(f0_bm_int2) Family: gaussian
Links: mu = identity; sigma = identity
Formula: f0mn ~ 0 + gender:attitude
Data: polite (Number of observations: 212)
Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup draws = 4000
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
genderF:attitudeinf 256.61 5.16 246.73 266.76 1.00 5037 2982
genderM:attitudeinf 137.23 5.87 125.37 148.66 1.00 5491 2936
genderF:attitudepol 238.93 5.08 229.06 248.85 1.00 5191 2912
genderM:attitudepol 126.28 5.82 114.88 137.71 1.00 5455 3018
Further Distributional Parameters:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sigma 39.13 1.94 35.51 43.18 1.00 4975 3159
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).conditional_effects(f0_bm_int2, "gender:attitude")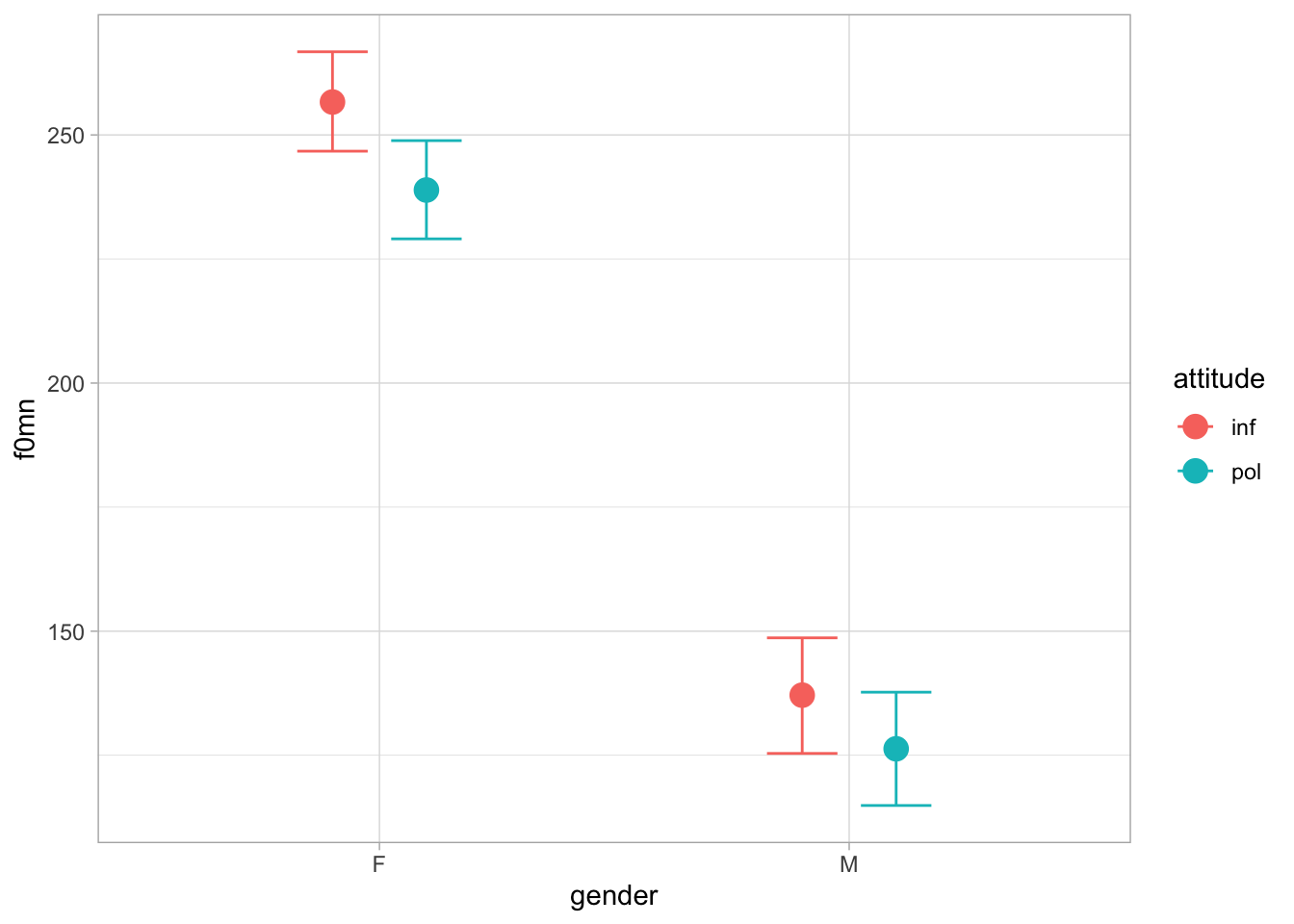
f0_bm_int2_draws <- as_draws_df(f0_bm_int2)f0_bm_int2_draws <- f0_bm_int2_draws |>
mutate(
f_pol_inf = `b_genderF:attitudepol` - `b_genderF:attitudeinf`,
m_pol_inf = `b_genderM:attitudepol` - `b_genderM:attitudeinf`,
)library(posterior)This is posterior version 1.6.1
Attaching package: 'posterior'The following objects are masked from 'package:stats':
mad, sd, varThe following objects are masked from 'package:base':
%in%, matchf0_bm_int2_draws |>
summarise(
mean_diff = mean(m_pol_inf), sd_diff = sd(m_pol_inf),
lo_diff = quantile2(m_pol_inf, probs = 0.025), hi_diff = quantile2(m_pol_inf, probs = 0.975)
) |>
round()