8 General discussion
Rather than trying to disprove a given hypothesis or showing that one is primary, we argue that it is useful to consider the inter-relationships between these different hypotheses.
—Winter and Röttger (2011)
This dissertation investigated the influence of consonant voicing on vowel duration by focussing on production aspects of vowel-consonant sequences. As a cross-linguistic tendency, known as the “voicing effect,” vowels are shorter when followed by voiceless consonants and longer when followed by voiced ones. Several proposals as to what mechanisms underlie this tendency have been put forward, but no account has won consensus. I carried out two studies to investigate durational and articulatory properties of vowels and consonants in Italian, Polish, and English. Four original publications presented and discussed the results from these studies. 4 and 5 show that the duration of the interval between the releases of the stops of a disyllabic word is not affected by the voicing of the second stop in Italian, Polish, and English. On the other hand, the release-to-release interval of English monosyllabic words is longer when the second consonant is voiced. The results in 6 suggest the existence of a statistical correlation between vowel duration and degree of tongue root advancement, such that longer vowel durations correspond to greater tongue root advancement. Finally, in 7 I speculate that the timing of the stop closure is modulated by the presence of emerging voiceless pre-aspiration, so that either enhancement of pre-aspiration delays closure or its prevention anticipates it. This chapter provides an over-arching synthesis of the account proposed here in light of the observed patterns, and discusses the implications for theories of speech production.
8.1 A pluralist view
One of the questions posed at the beginning of the dissertation (2.1) concerned the source of the voicing effect and the diachronic pathway to its emergence. Each previous articulatory account of the voicing effect, reviewed in 1.5, ascribes the driving force behind this phenomenon to a different individual property of speech. According to the compensatory temporal adjustment account (Lindblom 1967; Slis & Cohen 1969a; Slis & Cohen 1969b; Lehiste 1970a; Lehiste 1970b), there is a trading relationship between the duration of vowels and that of the following consonant. The account of rate of stop closure transition states that the rate of the closing gesture of voiceless stops is higher than that of voiced stops (Öhman 1967a; Chen 1970). As a consequence, full closure is achieved earlier relative to the onset of the closing gesture when the stop is voiceless. A third notable account, that of laryngeal adjustment (Halle & Stevens 1967; Halle, Stevens & Oppenheim 1967; Chomsky & Halle 1968), holds that the achievement of stop closure in voiced stops is slower than that of voiceless stops to allow for enough time to produce a glottal configuration that is suitable for voicing during closure.
The results of Study I (4, 6, 7) and II (5) bring together aspects of these three accounts, and allow us to formulate a holistic account of the voicing effect, discussed in the following paragraphs, that incorporates different components. Two important aspects of the account proposed here are: (1) the temporal stability of the interval spanning the vowel-consonant sequence, and (2) the timing of the vowel-consonant (VC) boundary within that interval. While (1) draws on the compensatory temporal adjustment account, (2) is informed by the account of rate of closure and that of laryngeal adjustment.
In 4, we saw that Italian and Polish disyllabic words show properties of temporal stability, as expected by an account of compensatory adjustment. In particular, it was observed that the duration of the interval between the release of the first consonant and the release of the second in CVCV words (the release-to-release interval) is not affected by the voicing category of the second consonant. However, while the original compensatory account states that the stop closure duration determines the duration of the preceding vowel, the formulation of the account proposed here takes a more neutral position. More specifically, I argue that the timing of the VC boundary within the release-to-release interval determines the durations of both vowel and stop closure, as discussed in 4.4.2.
The second fundamental aspect of the account put forward here is that the timing of the VC boundary is modulated by aspects that would fall under the rate of closure and the laryngeal adjustments accounts. The ultrasound and EGG data from Study I, as discussed in 6 and 7, suggest that mechanisms independent from closure duration per se can act upon the timing of the VC boundary and, indirectly, on the duration of stop closure. For one, tongue root position can influence the timing of the boundary by delaying it to allow for greater tongue root advancement, which is known to facilitate voicing during the production of the stop closure (6). Second, the development of pre-aspiration can influence the timing of the VC boundary by delaying or anticipating it depending on whether pre-aspiration is enhanced or prevented (7).
In Study II, discussed in 5, it was found that the temporal properties of English disyllabic words resemble those of Italian and Polish. As in the latter languages, the duration of the release-to-release interval is not affected by the voicing of the post-vocalic stop. However, the situation is different in English monosyllabic words. In this context, voicing does affect the duration of the interval, and the interval is longer when the post-vocalic consonant is voiced. The fact that voicing affects release-to-release duration was ascribed to mechanisms of contrast enhancement driven by perceptual factors (5.1.1). In 5, I stipulate that the acoustic temporal stability of the release-to-release interval can be derived from an articulatory account of gestural phasing. While 5.1.1 only briefly outlined the main components of this articulatory account, the following section contains a more detailed description.
8.1.1 Gestural phasing
As proposed in 5, the temporal stability of the release-to-release interval is compatible with a certain view of the gestural organisation of vowel and consonants within the domains of the syllable and the word. In this section, I review the principles of Articulatory Phonology and vowel-to-vowel isochrony, and I show how the combination of these two frameworks in a single gestural phasing account can shed light on the durational patterns of the voicing effect discussed in this dissertation.
Within the framework of Articulatory Phonology (Browman & Goldstein 1986; Browman & Goldstein 1988; Browman & Goldstein 2000; Goldstein, Byrd & Saltzman 2006; Goldstein & Pouplier 2014), speech gestures can be implemented according to two coupling modes: in-phase or anti-phase mode. When two or more gestures are in an in-phase relation, they are initiated in synchrony. If two or more gestures follow an anti-phase coupling mode, the gestures are implemented sequentially, and one gesture starts when the preceding one has reached its target. These two coupling modes can account for temporal aspects observed in the relative phasing of consonants and vowels.
![Gestural organisation patterns for onsets (a) and codas (b). C = consonant, V = vowel [design based on @marin2010].](img/gest-align.png)
Figure 8.1: Gestural organisation patterns for onsets (a) and codas (b). C = consonant, V = vowel (design based on Marin & Pouplier 2010).
Marin & Pouplier (2010) show that onset consonants in American English are in-phase with respect to the vowel nucleus and anti-phase with each other. Such phasing pattern establishes a stable relationship between the centre of the consonant (or consonants in a cluster) and the following vowel. Independent of the number of onset consonants, the temporal midpoint of the onset (the so-called “C-centre”) is maintained at a fixed distance from the vowel, such that an increasing number of consonants in the onset does not change the distance between the vowel and the C-centre (Figure 8.1a). On the other hand, coda consonants are in an anti-phase relation with the preceding vowel and between themselves. When consonants are added to the coda, they are sequentially implemented. Temporal stability in codas is found in the lag between the vowel and the left-most edge of the coda, which is not affected by the number of coda consonants (Figure 8.1b). Other studies found further evidence for the synchronous and sequential coupling modes Marin & Pouplier (2014), although the use of one mode over the other depends on the language and the consonants under study (Pouplier 2012). Consonants can thus be said to follow either a C-centre or a left-edge organisation pattern depending on whether they are in-phase or anti-phase with the vocalic gesture.
Phasing modes are defined within a unit that corresponds to the traditional syllable, or, in other words, relative to the following vowel for onsets and the preceding vowel for codas. Less is known about the relation between segments belonging to different syllables and how syllables are timed and phased within words. Öhman (1967b) and Fowler (1983) propose that vocalic gestures are implemented according to a rhythmic programme and that consonantal (constriction gestures) are superimposed on the vocalic gestural stream. Furthermore, the authors argue that the timing of vocalic gestures follows a regular cyclic pattern, which is in turn responsible for the rhythmic patterns of speech. Fowler (1983) reviews a collection of findings from speech production, perception, and phonological patterns that support the idea of a cyclic production of vowels.
A consequence of the cyclic production of vowels and the independence of the vocalic and consonantal gestures is that two consecutive vowels within a word would be at a stable temporal distance, independent of the nature and number of the intervening consonants. This hypothesis, however, is not borne out by the empirical evidence in Smith (1995), Zmarich et al. (2011) and Zeroual et al. (2015). Using electromagnetic articulography, these studies find that the distance between two vowels is greater when the intervening consonant is a geminate compared to when it is a singleton consonant. Furthermore, Jong (1991) finds only partial support for the independence of vowel and consonant gestures, based on the fact that the tail end of the opening gesture of the vowel is affected by the following consonant. These studies also find substantial inter-speaker variation in the particulars of the gestural implementation of vowel-consonant sequences.
While the strong prediction of vowel-to-vowel isochrony is not confirmed by data comparing singleton and geminate consonants, a weaker formulation of isochrony might still hold. A possible reason for why the isochrony breaks in the geminate context is that geminate consonants are a blend of two phasing patterns. For example, Smith (1995) and Zeroual et al. (2015) argue that their findings support the interpretation of geminates as two consonants produced sequentially. This would mean that the first part of the geminate is implemented anti-phase with the preceding vowel, while the second part is articulated in-phase with the following. The presence of an anti-phase gesture intervening between the vowels could be responsible for the disruption of the vowel-to-vowel isochrony. In other words, any consonant cluster made of heterosyllabic consonants would show absence of vowel-to-vowel isochrony. If this is the case, then isochrony would apply only in those cases where the intervening consonants are in-phase with the second vowel (see 9 for a set of hypotheses). This scenario is shown in Figure 8.2(a).
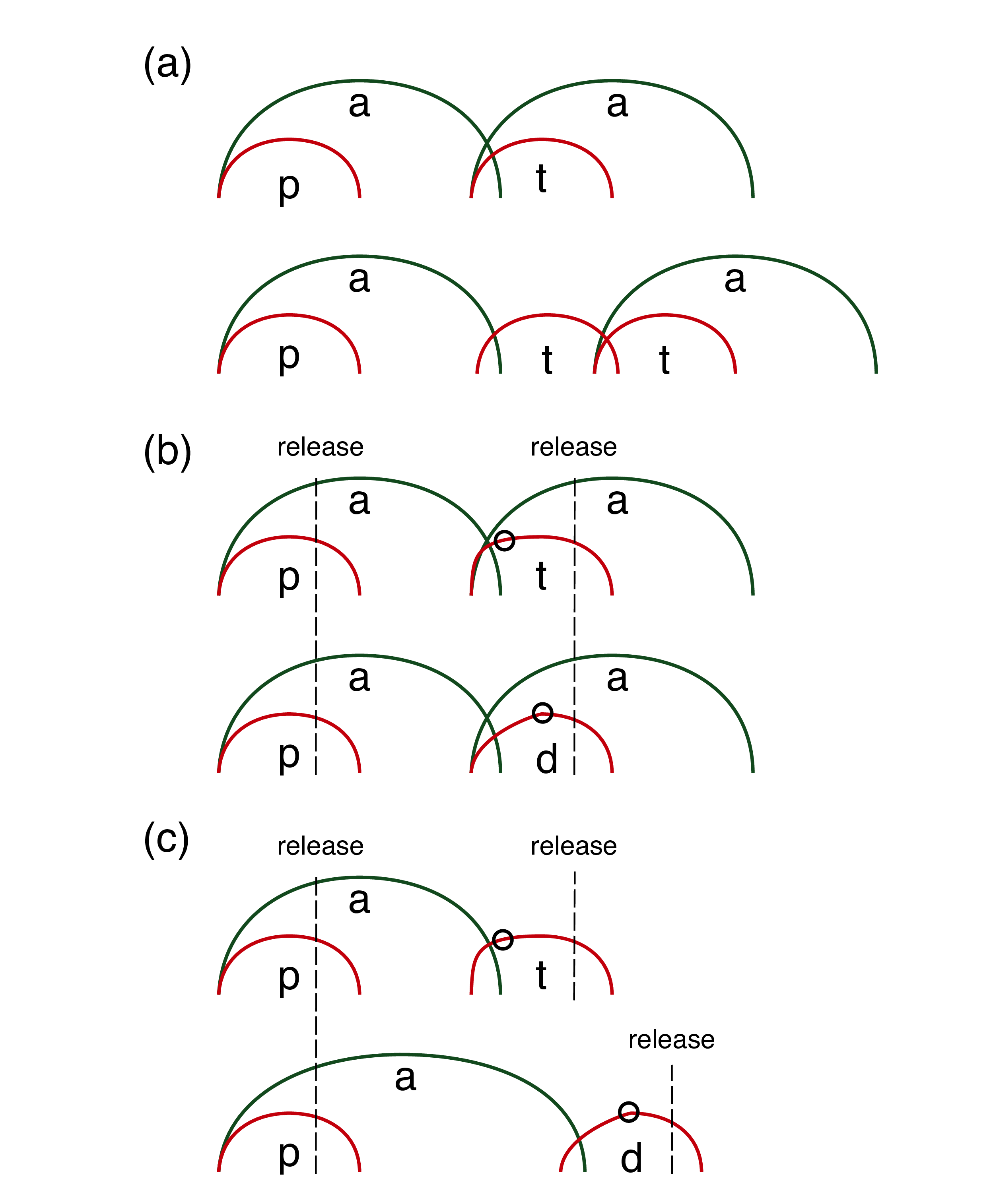
Figure 8.2: Schematics of the gestural phasing of vocalic and consonantal gestures in different contexts, which partially repeats fig:vv-cent-2 from p:en-relrel. The x-axis is time, while the y-axis can be interpreted as oral aperture for vowels and oral constriction for consonants. (a) shows singleton vs geminate stops, (b) voiceless and voiced stops in disyllabic words, and (c) voiceless and voiced stops in monosyllabic words. Note that in (a) the distance between the vowels increases in the geminate context, while it is stable in (b) and (c). The circles in (b) on the consonant gesture lines indicate the time of acoustic closure onset.
Turning now to the voicing effect, since CVCV words differing in C2 voicing include a singleton consonant, we can expect VV isochrony to apply. This is illustrated in Figure 8.2(b). Since onset consonants are in-phase with the following vowel, the timing of the gestural onset of voiceless and voiced stops in the second syllable of pata and pada respectively should also be identical. This is in part confirmed by the ultrasound tongue imaging data of Study I (see D). The duration of the interval between the acoustic release of C1 and the gestural onset time of C2 in CVCV words is not affected by the voicing status of C2, as discussed in 4 for Italian and Polish and 5 for English.
On the other hand, the velocity of the closing gesture is known to differ in voiceless vs voiced stops (Summers 1987).28 While the timing of gestural onset is identical in both voicing contexts, the difference in closing velocity produces the observed acoustic pattern of the later timing of the acoustic VC boundary when the consonant is voiced than when it is voiceless. In Figure 8.2(b), the time of full oral closure is signalled by a circle on the displacement trajectory. Faster closing velocity in voiceless stops creates an early VC boundary, while a slow closing gesture generates a later VC boundary.
However, in tautosyllabic VC sequences, the consonant gesture is implemented anti-phase with the preceding vowel, meaning that the vocalic and consonantal gestures are produced sequentially. In such case, VV isochrony is broken and the duration of V1 can be modulated freely without proportionally affecting closure duration. This scenario is depicted in Figure 8.2(c). This is what is argued to have happened in English monosyllabic words, where the temporal distance between the releases of C1 and C2 differs depending on C2 voicing, as shown in 5. Raphael (1972) and Jong (1991) indeed find that, in English monosyllabic words, the vocalic gesture is held for longer when the following consonant is voiced and that the gesture onset of voiced stops is timed later during the production of the vowel relative to that of voiceless stops.
As a final note, in 4.4.2 I mentioned Tilsen’s selection-coordination model as a promising one in that it provides us with theoretical machinery to describe word-holistic patterns of gestural phasing (Tilsen 2013; Tilsen 2016). This aspect sets the selection-coordination model apart when compared with classical Articulatory Phonology, the focus of which is generally restricted to the level of syllables, as we have seen in the outline of the coupling modes above. However, a detailed development of a selection-coordination interpretation of the gestural phasing account proposed here is beyond the scope of this dissertation, and it is left to future research.
8.1.2 Diachrony, production, and perception
The composite account proposed in the previous sections is diachronic in nature, in so much as it reveals a possible historical pathway to the development of the voicing effect, rooted in production aspects of vowels and consonants. In particular, I argue that the voicing effect can emerge because of the temporal stability of VC sequences and the differences in timing of the VC boundary depending on the voicing of the post-vocalic consonant. Such an account assumes that the original scenario is one in which the duration of vowels and that of closures do not differ across voicing contexts. Durational differences can emerge via developmental learning and historical change in individual speakers and spread across the population.
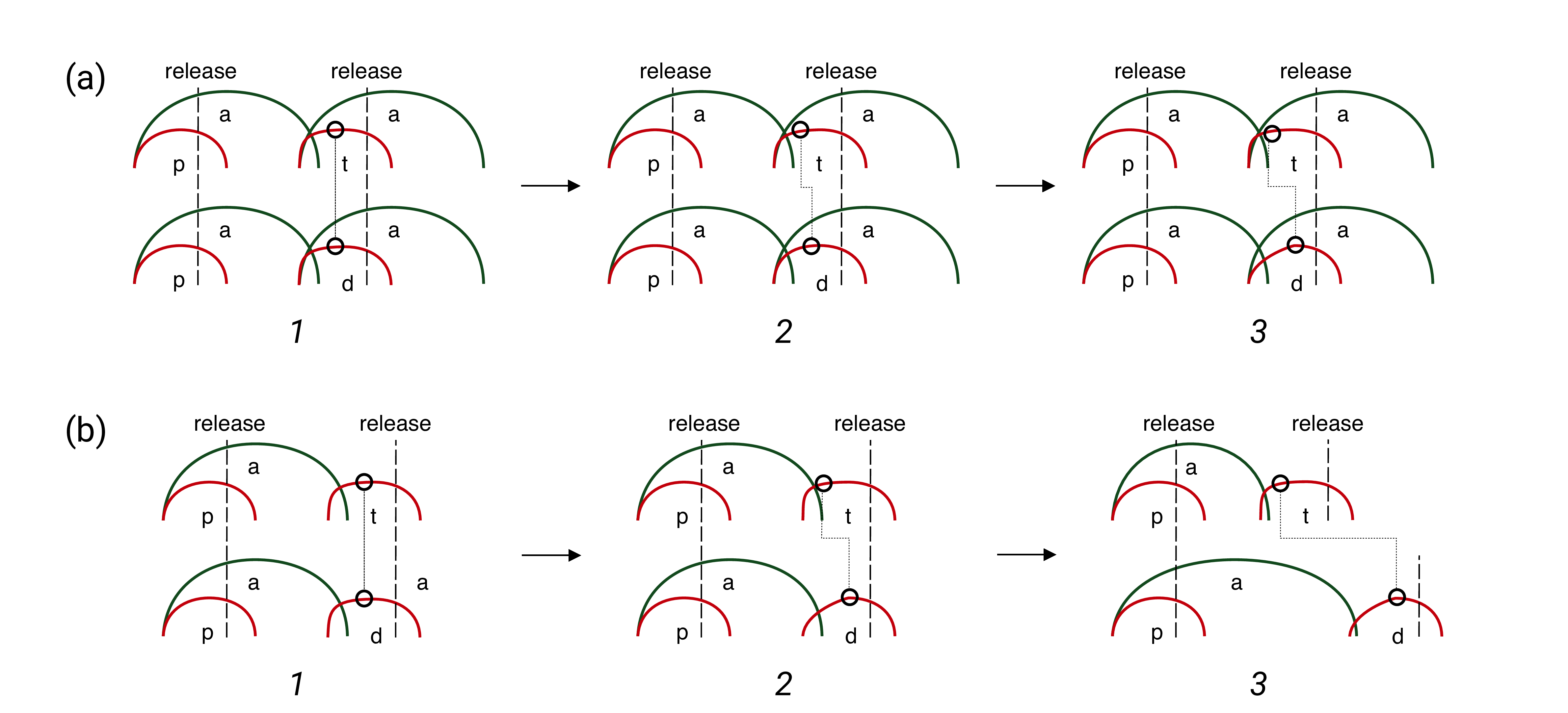
Figure 8.3: Schematics of the developmental/historical emergence of the voicing effect in disyllabic (a) and monosyllabic (b) words. See text for details.
Figure 8.3 illustrates how the emergence of the voicing effect in disyllabic (a) and monosyllabic (b) words with either a voiceless or a voiced post-vocalic stop is envisioned to work. For each type of word, the figure shows three stages that can be thought of as three stages in a continuum of developmental learning and/or the historical change of a language across generations (future work is needed to work out the full details of these scenarios). Starting with disyllabic words in (a) stage 1 (top left panel), the words pata and pada show an identical temporal profile. The release of the stops are indicated by a dashed line, while full oral closure (the acoustic VC boundary) is signalled by a circle on the profile of the second consonant. The timing of the vocalic and consonantal gestures (including the timing of the release and the VC boundary) coincide, as illustrated by the straight vertical lines indicating releases and connecting oral closures. In other words, there is no voicing effect, and both the duration of vowels and that of stop closures is not affected by voicing.
At stage 2, the timing of the VC boundary in the two voicing conditions has shifted. There is now a voicing effect: vowels are shorter when followed by voiceless stops and longer when followed by voiced stops, and vice versa voiceless stop closures are longer and voiced stop closures shorter. This change is brought about by the differing closing velocity of voiceless and voiced stops. In relation to the VC boundary shift, three scenarios are possible: (1) the VC boundary shifts leftwards in the voiceless context, (2) the VC boundary shifts rightwards in the voiced context, (3) both (1) and (2) are implemented. Only diachronic data will be able to indicate which of these three scenarios is the correct one, but possibly (3) is compatible with the finding of two mechanisms that can lead to the closure velocity differential and hence to a VC boundary shift. As discussed in 6 and 7, these mechanisms are tongue root advancement in voiced stops and the emergence of pre-aspiration in voiceless stops. The later closure onset of voiced stops gives enough time for the tongue root to advance (as a mechanism for sustaining closure voicing), while the earlier closure onset of voiceless stops masks glottal spread (a correlate of voicelessness) which otherwise would result in pre-aspiration. It goes without saying that other mechanisms not investigated here might also play a role, so I do not wish to attribute boundary shifts exclusively to these two mechanisms.
Finally, in (a) stage 3, the temporal distance between the VC boundaries in pata and pada has increased through time and has now reached a stable state. The absolute difference in vowel and closure durations will depend on the language and on how other factors, like perceptual ones, further modulate it. Note that throughout stages 1 to 3, the temporal stability of the release-to-release interval is maintained due to the preservation of vowel-to-vowel isochrony.
Turning to monosyllabic words in Figure 8.3(b), the bottom left panel in 1 illustrates the initial stage of pat and pad words where the temporal profiles are, as in (a)1, identical. There is no voicing effect. As in (a)2-3, the VC boundary in the voiceless and voiced contexts shifts in (b)2, and a voicing effect emerges. Now, as discussed in 5, the duration of the vowels can be modulated for contrast enhancement purposes by temporal shortening in the voiceless context and/or lengthening in the voiced one (the schematics in (b)3 shows the case where both shortening and lengthening occur). The temporal stability of the release-to-release interval is now disrupted. This is possible due to the absence of vowel-to-vowel isochrony (since there is no second vowel to temporally lock in monosyllabic words). Finally, note that the same contrast-enhancing perceptual biases that operate in the context of monosyllabic words can also operate in disyllabic ones, with the exception that vowel-to-vowel isochrony (and release-to-release temporal stability) is preserved in the latter.
The discussion in 4.4.2 hinted at an exemplar-theoretic account of the diachronic scenario outlined here. Under exemplar-based theories, speech processing operates on parameters the values of which are obtained from statistical distributions. At the early stages of the emergence of the voicing effect, the timing of the VC boundary (as produced by gestural phasing) would come from a distribution shared across voiceless and voiced stops. Deviations from this distribution are a consequence of the application of VC boundary shifting driven by physiological factors. The boundary shifting can then accumulate through time via a perception-production feedback-loop. Statistical sub-distributions in the timing of the VC boundary would thus start emerging for voiceless and voiced stops from the prior unique distribution. These sub-distributions can then act as distributions from which timing information is directly obtained during speech processing. At this point, while the original physiological biases might still be in place, the presence of independent sub-distributions blurs the statistical relationship among durational measures, and, as argued in 4.4.2, the true underlying mechanisms are difficult if not impossible to recover from synchronic data.
An exemplar-based view was chosen as an illustrative example of the cognitive mechanisms behind the emergence of the voicing effect, although other frameworks might as readily account for the patterns discussed in this dissertation. Future work is warranted to weight the goodness of each individual framework in doing so.
While the account proposed here is based on production mechanisms, it cannot be completely excluded that the production differences observed and stipulated here are a consequence of perceptual biases. In such a scenario, there could be a design feature of the perceptual system that generates the differential duration percept, even when there is no such difference in the acoustic output/input. An example from the domain of vision illustrates this possibility. When looking at a wheel spinning in a clockwise direction, the observer will see the wheel rotating counter-clockwise when the rotation speed exceeds a threshold. There is nothing in the mechanics of a wheel spinning around its axis that can explain this perceptual fact. Rather, visual processing has a design feature (for example, vision refresh rate) that creates the illusion of the wheel spinning in the opposite direction. In this example, the wheel and its percept are two clearly separable ontological entities, so that the percept cannot change how the wheel is spinning. In the case of speech, however, a bias in the perceptual system can (and very often does) result in differences in production.
Teasing apart production and perceptual mechanisms in speech is more difficult than in the spinning wheel case, since production and perception operate within a single agent, i.e. the speaker/hearer. On the other hand, when we can find independent physical explanations behind production biases, we can consider them design features of the production system, and not just a consequence of perceptual biases. Since in the case of voicing there are independent production reasons for the observed patterns to exist, we can assume that, while perceptual biases can hook on the vowel duration differences as a cue to voicing and enhance such contrast, these differences emerge due to a production mechanism in the first place.
8.2 On cross-linguistic differences
The second aim of the dissertation was concerned with cross-linguistic differences in the development and implementation of the voicing effect. As discussed in 1, the degree of the voicing effect is generally thought to vary depending on the language. Allegedly, English is the language showing the biggest effect, while the effect is smaller in Italian and possibly absent in Polish. However, Papers I and II indicate a somewhat different scenario. A direct comparison of the data from Study I and II is not straightforward, given the different materials used in the two studies, but it still provides us with some directions as to what difference, if any, there are between the languages in question. A Bayesian analysis of the effect of voicing in disyllabic words comparing English, Italian, and Polish (see C) suggests that, when controlling for differences in average baseline vowel duration and speech rate, there is no strong evidence for a difference in the magnitude of the voicing effect across these languages. Note, however, that no conclusive statement can be done in this regard, due to the low precision of the relevant estimates obtained in the meta-analysis.
As thoroughly discussed in 4.4.1, the magnitude of the voicing effect found in Study I for Italian aligns with previous work on this language, which is unanimously regarded as a voicing-effect language. Polish, on the other hand, has been claimed both to show a voicing effect (Slowiaczek & Dinnsen 1985; Nowak 2006; Malisz & Klessa 2008) or not (Jassem & Richter 1989; Keating 1984a; Strycharczuk 2012). In 4, it was argued that the Polish speakers surveyed in Study I do show the voicing effect, and that this effect is similar in magnitude to that of Italian. As mentioned in 4.4.1, it is possible that the null results reported in some of the literature are due to low statistical power, rather than absence of the effect (based on what discussed in 3.3).
Previous work (Sharf 1962; Klatt 1973), and in some part the results in 5, crucially indicate there is a tendency for the effect in English to be greater in monosyllabic than disyllabic words. It is important, then, that differences across languages are tested directly and within the same phonological contexts. An example of this approach is the study in Laeufer (1992), who shows that the effect in English and French is comparable when the vowel baseline duration is analogous.
Moreover, the results of the Bayesian meta-analysis of the English voicing effect (B) indicate that, while there is a clear positive effect of voicing on vowel duration, there is less certainty around the magnitude of such effect. Although the estimated range of values is between 55 and 95 ms, the analysis revealed a possibility for publication bias in favour of larger effects, meaning that the obtained values might be overestimated. Note also that there could be differences in speech rate across studies which cannot be controlled for, and older studies might have obtained data based on lower speech rates (which could explain the greater baseline vowel duration in these studies). The smaller effect found in Study II is indicative of such differences. For example, the intercept estimate of vowel duration before voiceless stops is about 125 ms in Study II, but the average vowel duration in the meta-analytical data is 150 ms. Although the voicing effect does not scale linearly with vowel duration, as suggested by Ko (2018), slower speech rates (i.e. longer vowel durations) would correspond to a greater effect of voicing.
Tanner et al. (2019) argue that the effect they found in spontaneous speech is smaller than that of laboratory speech reported in previous studies. However, when their results are compared to those of Study II, this apparent difference is substantially reduced. The ratio of the difference in vowel duration in Tanner et al. (2019) is estimated to be between 1 and 1.16. The ratio in Study II is between 1.03 and 1.17, a range that is virtually identical to that of Tanner et al. (2019).
While there is indication that the voicing effect is similar across some languages in some contexts, I am not claiming that the voicing effect is necessarily universal. Especially in the case of monosyllabic words, as argued above, language-specific perceptual enhancement can modulate the magnitude of the effect. For example, Tanner et al. (2019) demonstrate that, although not unambiguously, the effect of voicing on vowel duration in monosyllabic words differs across varieties of English. More work is needed to assess cross-linguistic differences with a sufficiently sampled dataset and by experimental procedures designed to reduce phonological differences.
8.3 Embracing variation and accepting uncertainty
The third objective of this dissertation focussed on research methods and practices in light of the principles of Open Science (3.3). The planning and execution of research were carried out with openness and transparency in mind. Following state-of-the art recommendations on how to curate and share research objects (Marwick, Boettiger & Mullen 2017; Berez-Kroeker et al. 2018; Nüst, Boettiger & Marwick 2018), the data, code, documentation, and software information have been made available as a research compendium on the Open Science Framework (https://osf.io/w92me/, Coretta 2020). Data and code have been released under a Creative Commons Attribution 4.0 International license and a MIT licence respectively, so as to facilitate and encourage re-use and attribution. Three R packages were developed while conducting this research as complementary software: speakr (Coretta 2019b), tidymv (Coretta 2019c), and rticulate (Coretta 2018b).
Attention has been given in reporting the results from the statistical analyses in a way commensurate with the weight of the evidence provided. As Vasishth & Gelman (2019) put it, “conclusions based on data are always uncertain, and this is regardless of whether the outcome of the statistical test is statistically significant or not.” Rather than focussing on a dichotomous distinction between “significant” and “non-significant,” greater emphasis has been put on parameter estimation and quantification of uncertainty. This approach culminated in Study II with the full adoption of the framework of Bayesian statistics. What this dissertation as a whole hopefully highlights is the importance of embracing variation and accepting uncertainty, not as a detrimental aspect for science, but rather as a necessary step in the cumulative enterprise of knowledge acquisition.
One aspect not directly touched upon here is how Open Science practices affect collaboration among multiple researchers. In fact, the workflow followed here has a ready application in collaborative environments. For example, the Git versioning software has built-in functionalities which can streamline collaboration, like the ability to cleverly merge changes applied by different team members on the same file. The same workflow can be used not only for data collection and analysis, but also for collaborative writing. Although most institutions nowadays are equipped with self-hosted servers, platforms like GitHub, GitLab, and the Open Science Framework provide free servers and software solutions that facilitates research teamwork. Finally, sharing data and code can further foster scientific collaboration (McKiernan et al. 2016; Klein et al. 2018). In this regard, it is hoped that the linguistic community at large will be able to appreciate the innumerable benefits of Open Science, and that researchers in this discipline will decide to adopt and cultivate its principles.