In this tutorial, you will analyse data from Song et al. 2020. Second language users exhibit shallow morphological processing. DOI: 10.1017/S0272263120000170.
shallow <-read_csv("data/shallow.csv")
Rows: 6500 Columns: 11
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (8): Group, ID, List, Target, Critical_Filler, Word_Nonword, Relation_ty...
dbl (3): ACC, RT, logRT
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
shallow
The study consisted of a lexical decision task in which participants where first shown a prime, followed by a target word for which they had to indicate whether it was a real word or a nonce word.
The prime word belonged to one of three possible groups (Relation_type in the data) each of which refers to the morphological relation of the prime and the target word:
Unrelated: for example, prolong (assuming unkindness as target, [[un-kind]-ness]).
Constituent: unkind.
NonConstituent: kindness.
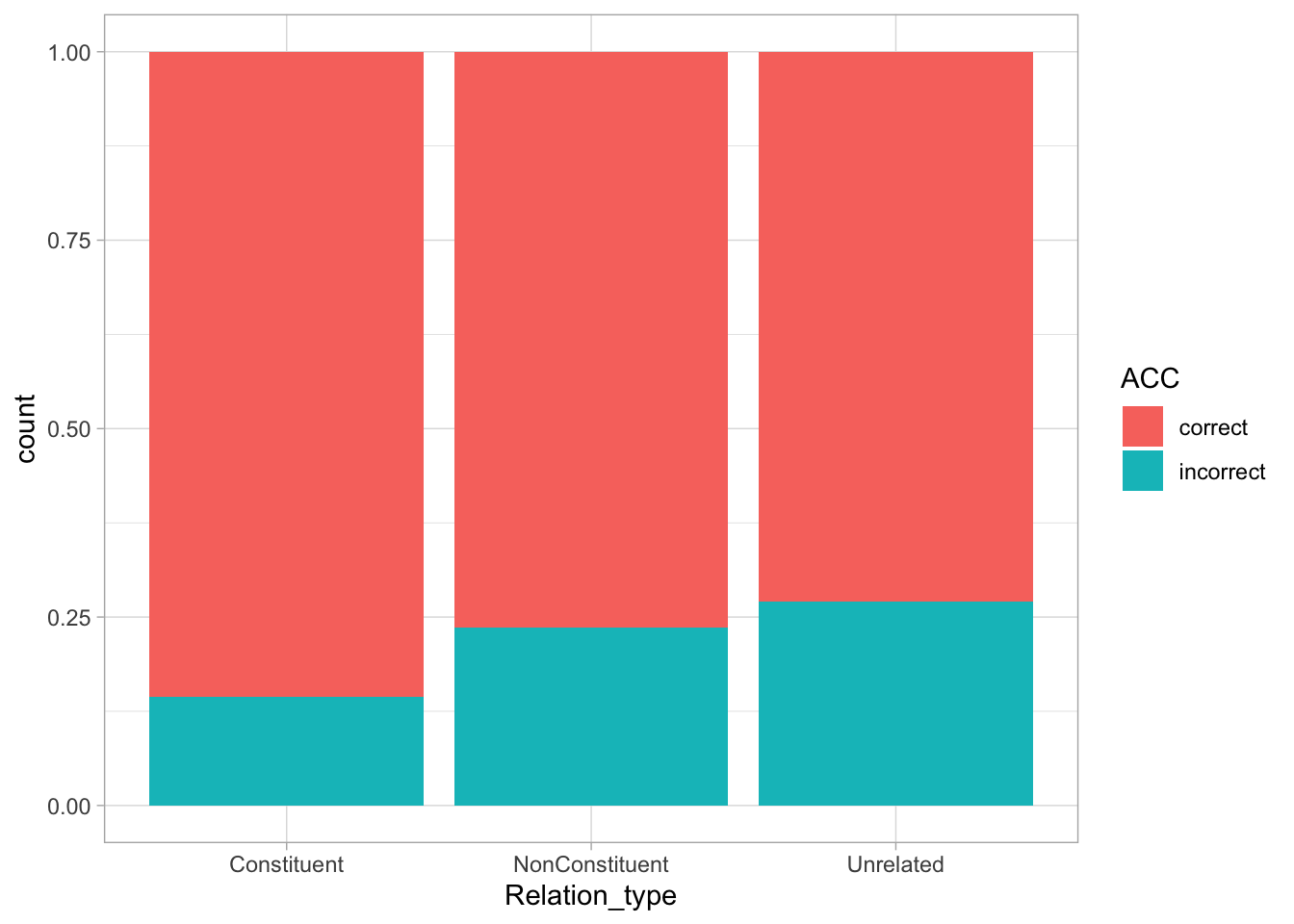
The expectation is that lexical decision for native English participants should be facilitated in the Constituent condition, but not in the Unrelated and NonConstituent conditions (if you are curious as to why that is the expectation, I refer you to the paper).
Let’s interpret that as:
The Constituent condition should elicit better accuracy than the other two conditions.
The study compared results of English L1 vs L2 participants and of left- vs right-branching words, but for this tutorial we will only be looking at the L1 and left-branching data. The data file also contains data from the filler items, which we filter out.
Let’s have a look at a plot that shows accuracy based on relation type.
shallow_filt %>%ggplot(aes(Relation_type, fill = ACC)) +geom_bar(position ="fill")
Modeling binary variables
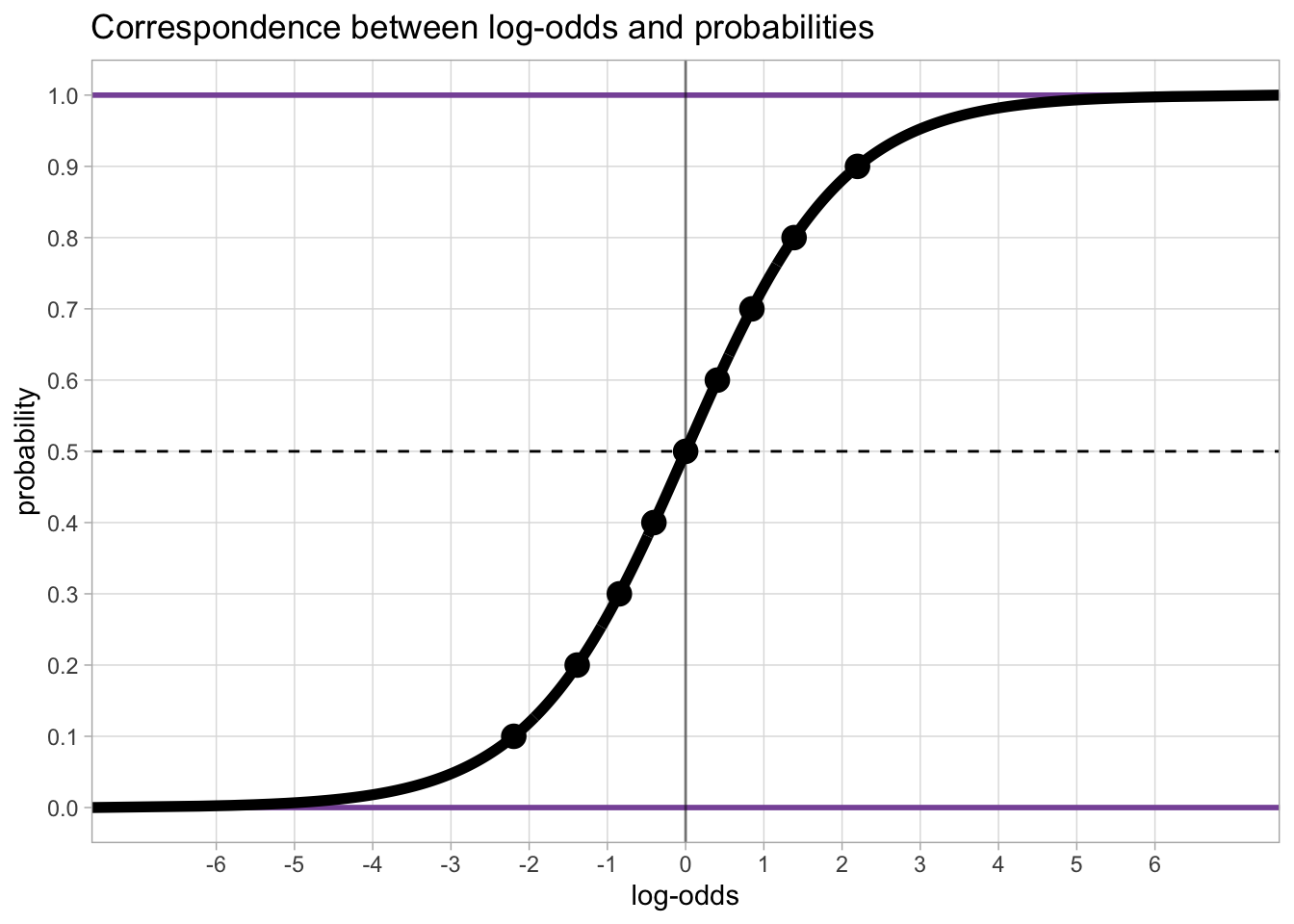
Accuracy (ACC) is a binary variable and to model the probability of a binary variable we need to use the Bernoulli family. Moreover, since probabilities are bounded between 0 and 1 and linear models expect unbounded variables, the estimates of the model will be in log-odds.
This is how log-odds are related to probabilities.
Now, fit a model with brm(). Here’s some tips:
In the formula, you want to include ACC as the outcome and Relation_type as the predictor.
This time, you have to specify family = bernoulli, to use the Bernoulli family (Gaussian is the default).
Remember to use shallow_filt as the data.
Then check the model summary with summary(). What does it tell you?
Compare what you understand from the model summary with the model of the plots (use conditional_effects() to get the plot).
Challenge
If you feel like and you have the time, try to run the model using both L1 and L2 data. You will have to include Group as a predictor and make sure you also include an interaction Group:Relation_type.