trajectories <- read_csv("./data/nichols-2018/tulemupepelako.csv")
trajectoriesVowel formants trajectories and tidy data
Phonetics
R
With the advent of more powerful statistical methods for assessing time series data, it is now becoming more common to compare whole vowel formant trajectories rather then just using average values.
In this post I will show how to tidy a formant measurements dataset and plot formants using the tidyverse (Wickham 2017).
1 From wide to long
To illustrate the process, I will use formant data that was kindly provided by Stephen Nichols.
Let’s first read in the data.
The dataset contains formant values of F1-F3 at 5% intervals for the vowels in the word tulemupepelako ‘we are praying for her’ (Bemba, [bemb1257]).
In the first step, we will create two columns, one with the formant/interval label and one with the formant value, using pivot_longer().
trajectories_long <- pivot_longer(
trajectories,
F1_05:F3_95,
names_to = "formant_int",
values_to = "value")
trajectories_longThe next step is to separate the formant_int column into two columns: one for formant, and one for interval. The argument convert = TRUE ensures that the interval column is converted into a numeric column.
trajectories_sep <- separate(
trajectories_long,
formant_int,
c("formant", "interval"),
convert = TRUE
)
trajectories_sepNow we can put back the formant labels into one column each. We can achieve this with pivot_wider(), the counterpart of pivo_longer().
trajectories_wide <- pivot_wider(
trajectories_sep,
names_from = formant,
values_from = value
)
trajectories_wideWe now have a dataset with separate columns for each formant and individual rows for each vowel interval.
1.1 The pipe
All the individual steps above can be chained by using the pipe %>%. What the pipe does is simply “transferring” the output of the function before it as the input of the function after it.
trajectories <- trajectories %>%
pivot_longer(F1_05:F3_95, names_to = "formant_int", values_to = "value") %>%
separate(formant_int, c("formant", "interval"), convert = TRUE) %>%
pivot_wider(names_from = formant, values_from = value)2 Plot
We can finally plot the formant trajectories.
trajectories %>%
ggplot(aes(x = interval)) +
geom_smooth(aes(y = F1), method = "gam", se = FALSE, colour = "#A7473A") +
geom_smooth(aes(y = F2), method = "gam", se = FALSE, colour = "#4B5F6C") +
geom_smooth(aes(y = F3), method = "gam", se = FALSE, colour = "#B09B37") +
facet_wrap(~ Vowel) +
ylab("Hertz")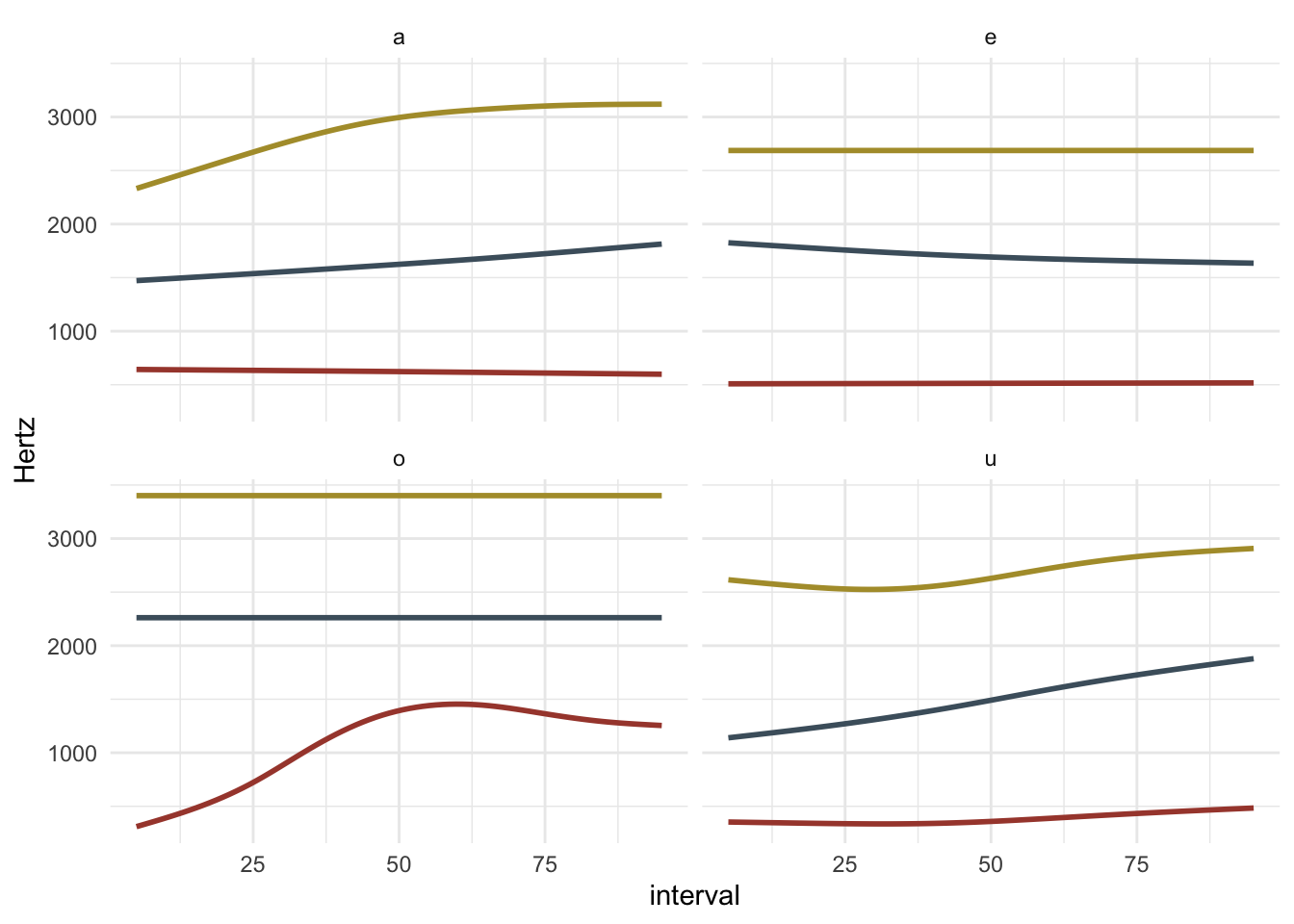
2.1 References
Wickham, Hadley. 2017. Tidyverse: Easily install and load the tidyverse.
Citation
BibTeX citation:
@online{coretta2018,
author = {Coretta, Stefano},
title = {Vowel Formants Trajectories and Tidy Data},
date = {2018-03-02},
url = {https://stefanocoretta.github.io/posts/2018-03-02-formants-tidy/},
langid = {en}
}
For attribution, please cite this work as:
Coretta, Stefano. 2018. Vowel formants trajectories and tidy data. https://stefanocoretta.github.io/posts/2018-03-02-formants-tidy/.