── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.2 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.1.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(plotly)
Attaching package: 'plotly'
The following object is masked from 'package:ggplot2':
last_plot
The following object is masked from 'package:stats':
filter
The following object is masked from 'package:graphics':
layout
library(coretta2018itapol)
Coretta 2018
The package coretta2018itapol can be installed from GitHub stefanocoretta/coretta2018itapol@devel (the devel branch contains the necessary data which is not yet available in main). The dlc_voff tibble has DLC spline data from the timepoint corresponding to the acoustically determined VC boundary in the CVCV target words.
In [2]:
data("dlc_voff")
We can ggplotly to determine the frame_id of data to be excluded (hovering over a contour shows the frame_id).
In [3]:
p <- dlc_voff |>filter(spline =="DLC_Tongue") |>ggplot(aes(X, Y, group = frame_id, text = frame_id)) +geom_path(alpha =0.2) +coord_fixed() +facet_wrap(vars(speaker))ggplotly(p, tooltip ="text")
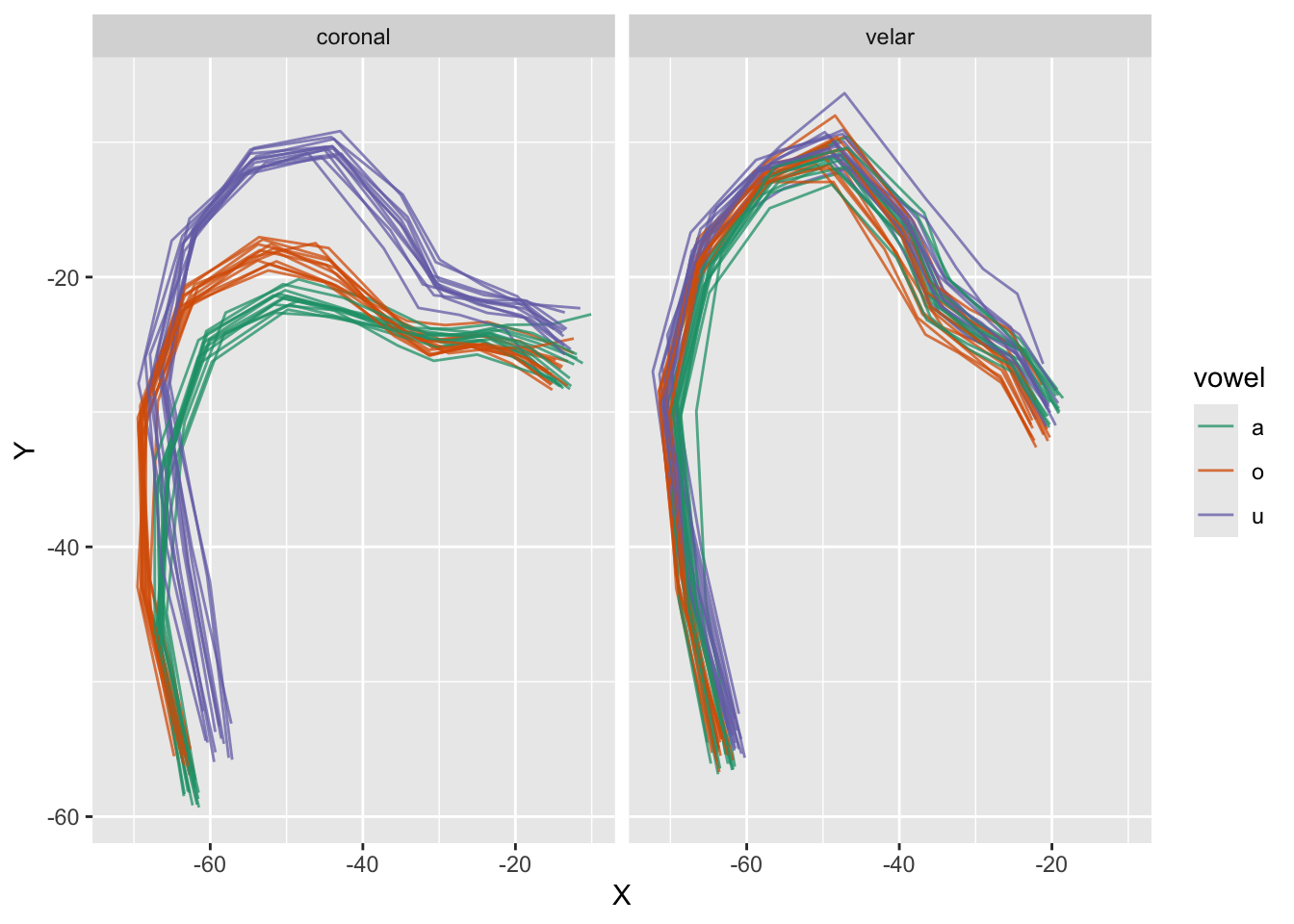
The following shows the tongue contours of participant PL04.
In [4]:
dlc_voff |>filter(speaker =="pl04", spline =="DLC_Tongue") |>ggplot(aes(X, Y, colour = vowel, group = frame_id)) +geom_path(alpha =0.75) +facet_grid(cols =vars(c2_place)) +scale_color_brewer(palette ="Dark2")
Let’s filter the data to remove wrongly tracked tongue contours. The filtered data is saved in dlc-voff-f. We also create two new columns as the interaction of existing columns, we calculate within-speaker z-scores for X/Y coordinates, and we convert speaker to a factor (needed for mgcv::gam()).