02 - Priors
Proposed distributions of vowel duration

Bayesian belief update
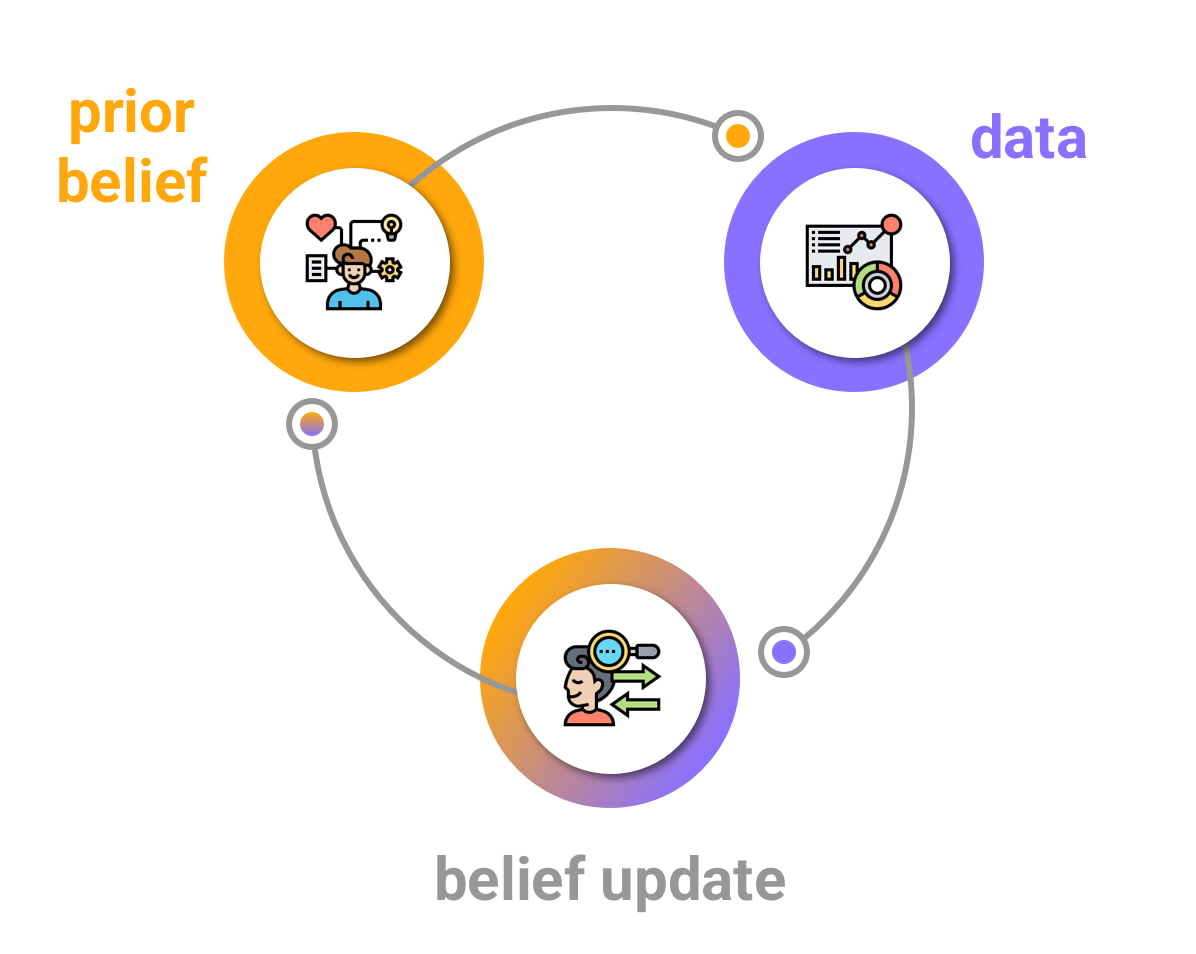
Prior probability distributions

The empirical rule

The empirical rule

The empirical rule

The empirical rule

The empirical rule

Prior for \(\mu\): plot

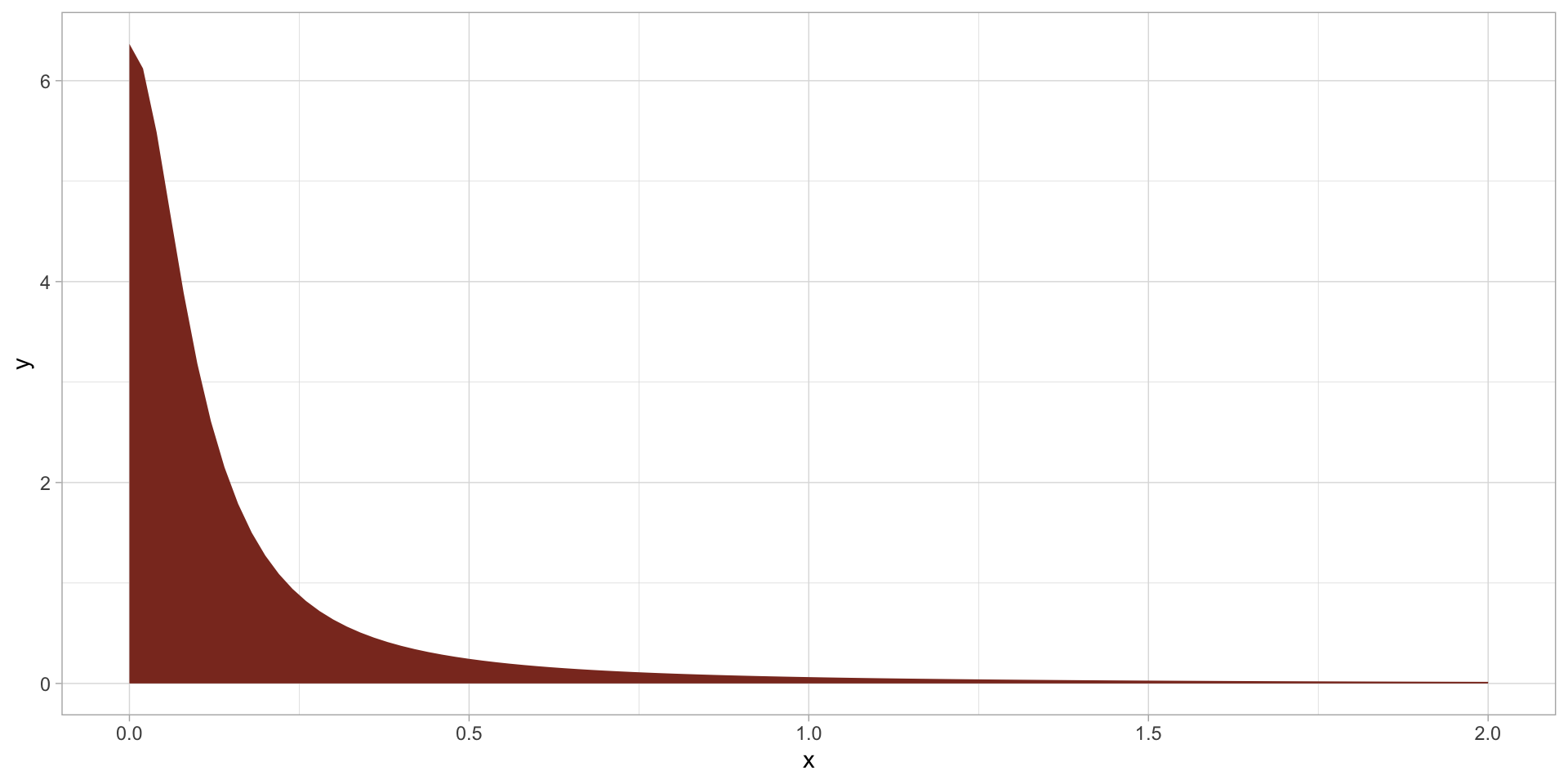
Prior for \(\sigma\): plot
Prior predictive checks: plot

Prior predictive checks: plot (zoom in)

Posterior predictive checks
