
Causal Inference for linguistics
Correlation is causation
2026-05-20
Causal effects

Directed acyclic graphs (DAGs)

Four path types
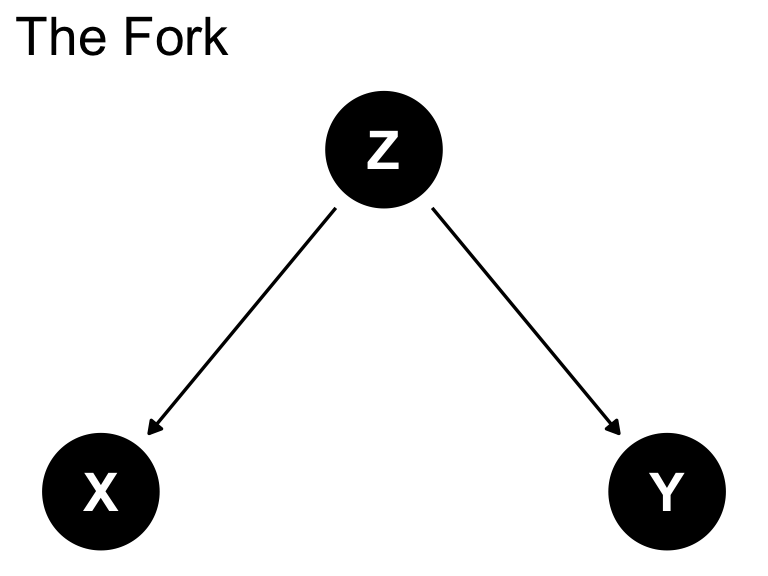
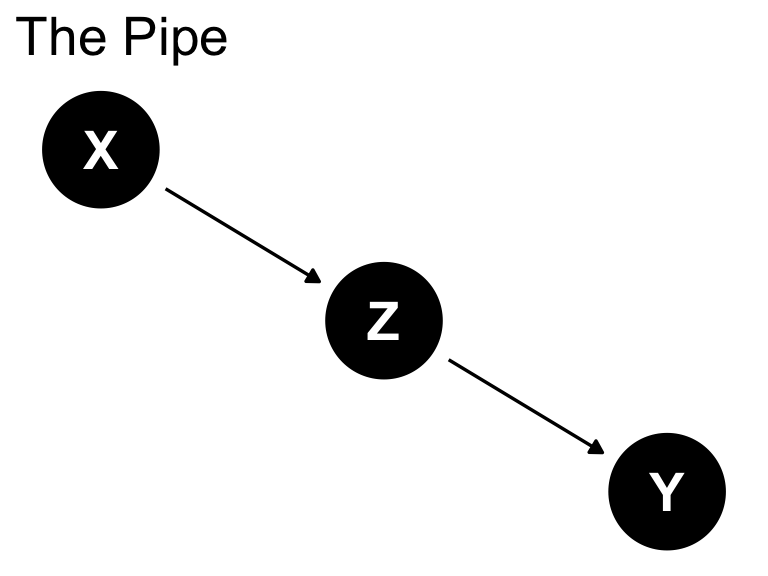
The Fork: Z is a confound

Confound: simulate
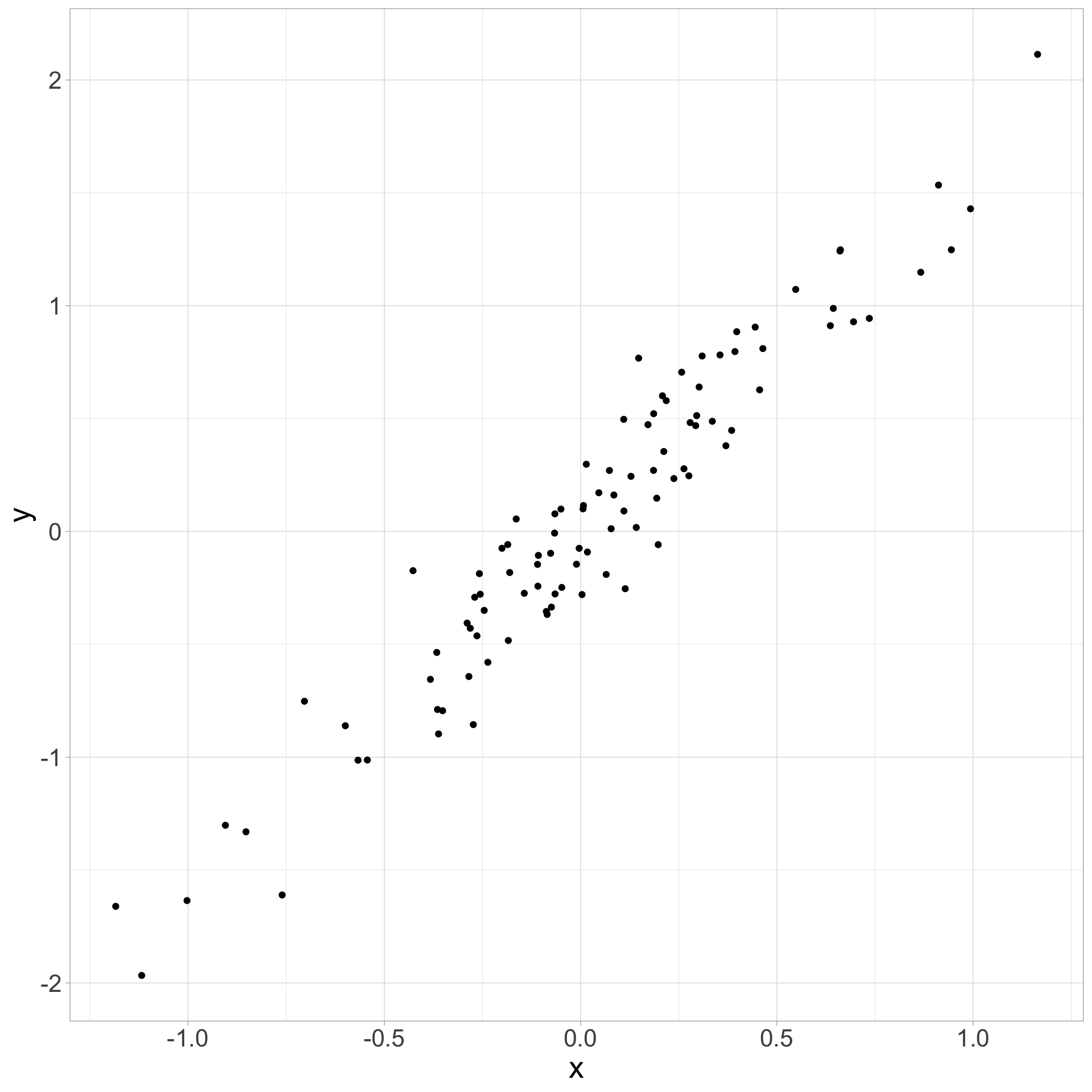
Confound: greater proficiency and code-switching

Confound: multicultural context

The Pipe: Z is a mediator

Mediator: simulate
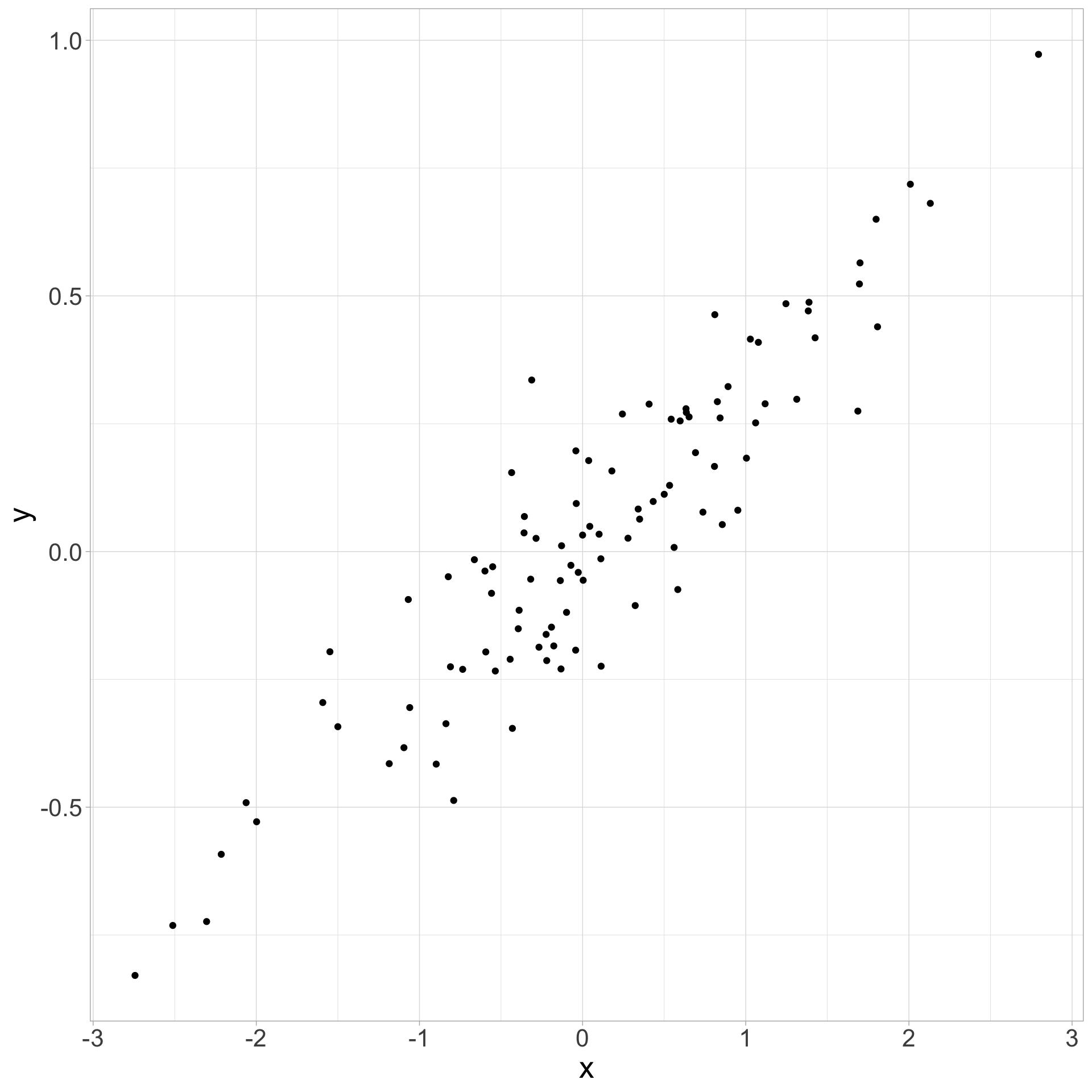
Mediator: bilingualism and executive function

Mediator: code-switching

Confound vs Mediator


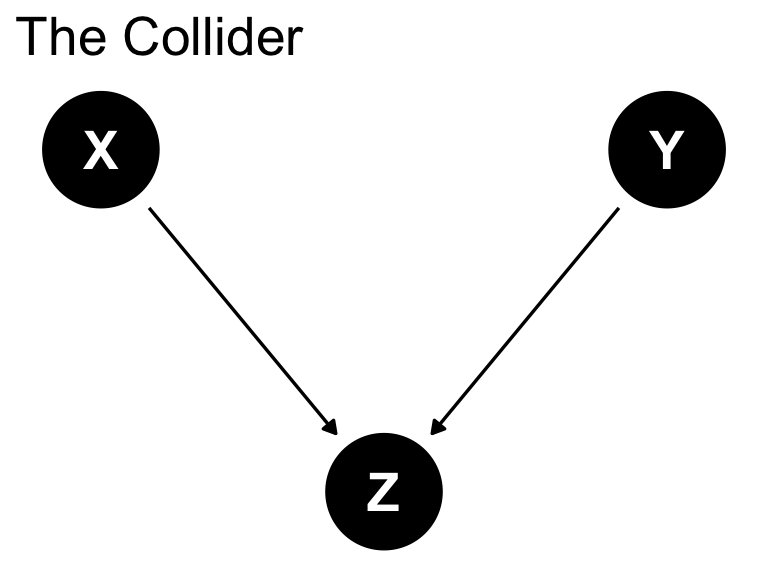
The Collider: Z is collider

Collider: newsworthiness and trustworthiness

Collider: simulate (plot)
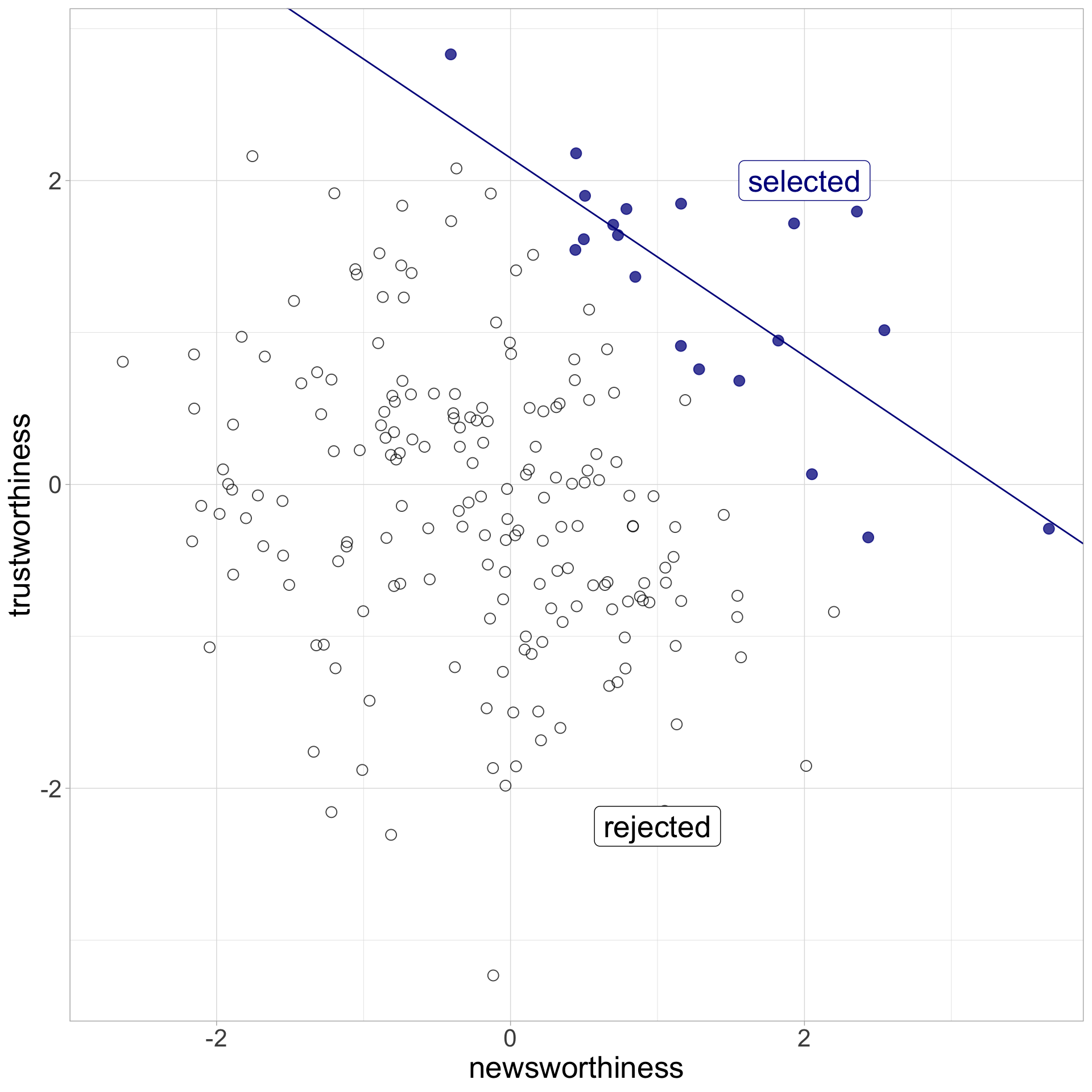
Collider: verb frequency and irregularity

Collider: verb saliency

Colonial history (confound)
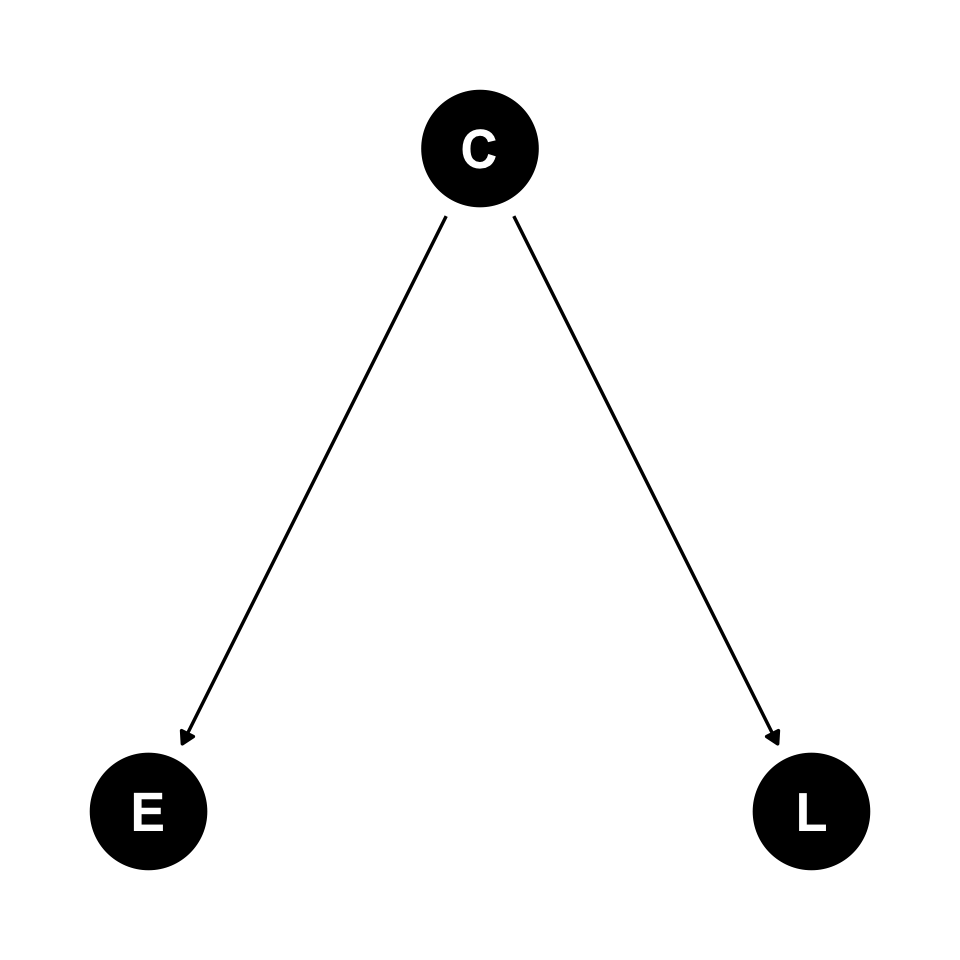
Colonial history: simulate

Colonial history: regression

Plant reliance (mediator)
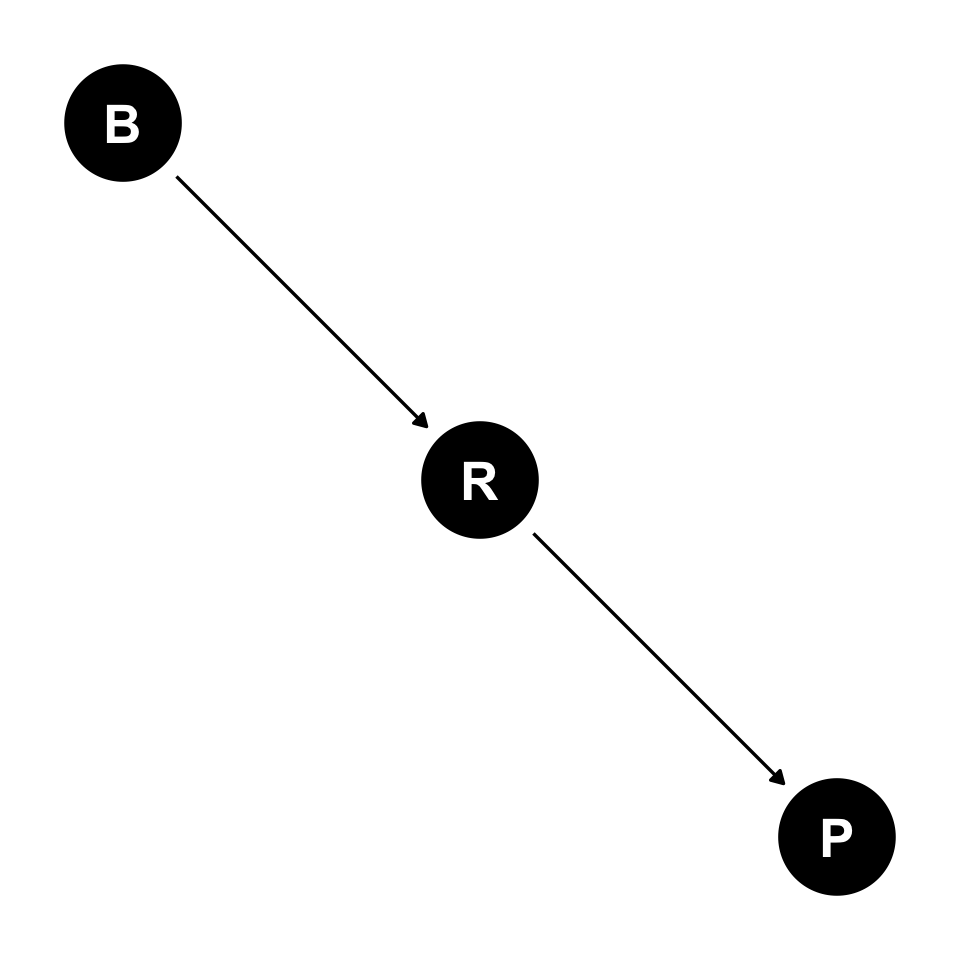
Plant reliance: simulate

Plant reliance: regression

Number of learners (collider)
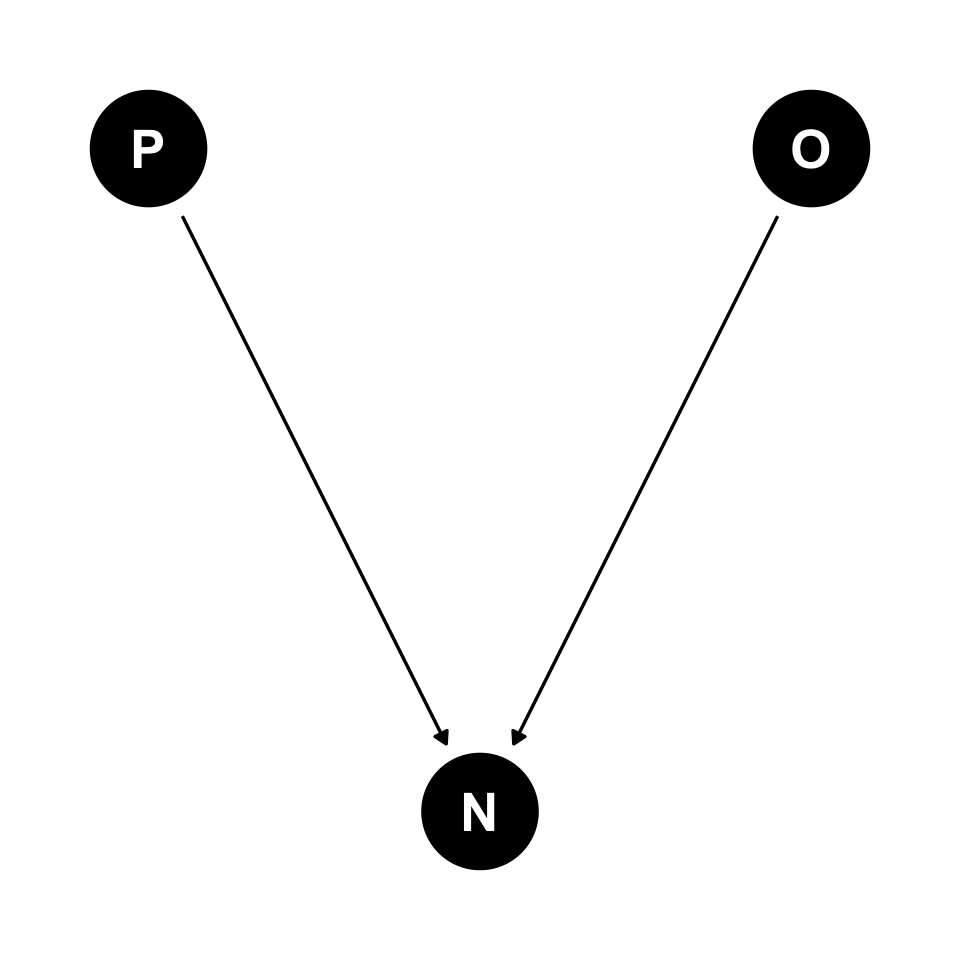
Number of learners: simulate
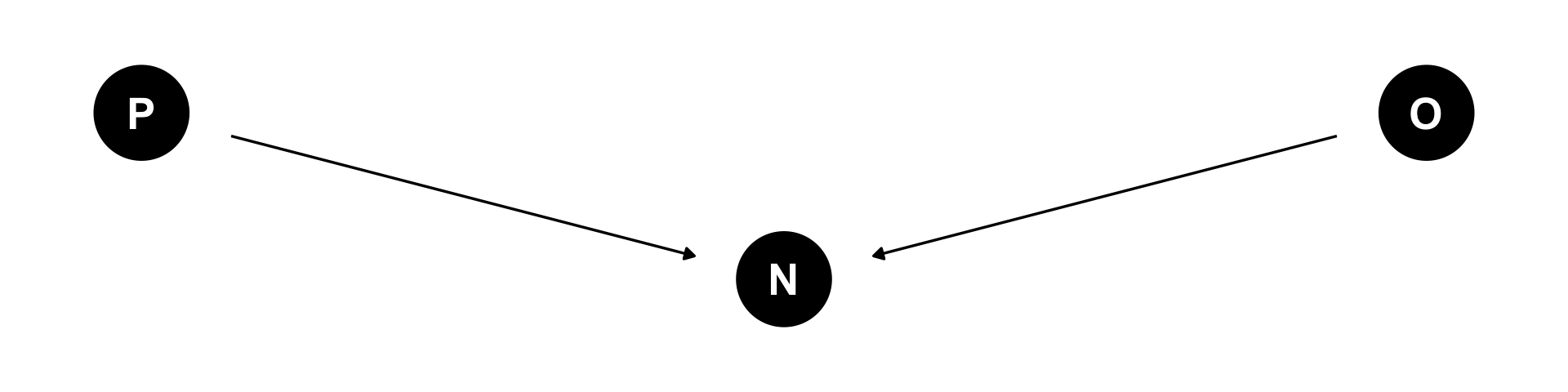
Number of learners: regression
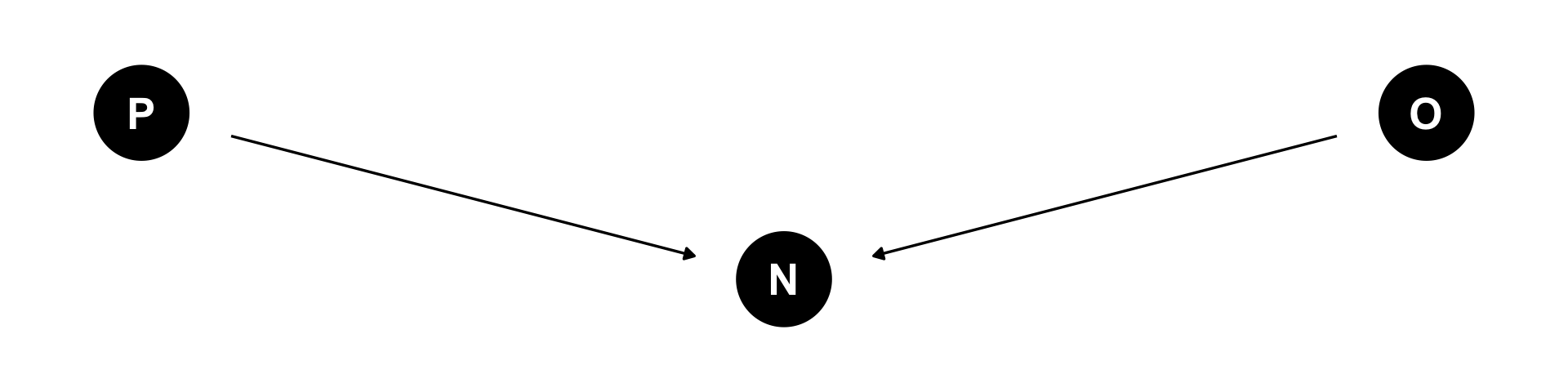
Conditional independences

\(P \not\!\perp\!\!\!\perp C\)
\(S \not\!\perp\!\!\!\perp C\)
\(S \not\!\perp\!\!\!\perp P\)
\(\perp\!\!\!\perp\) = “independent”
\(\not\!\perp\!\!\!\perp\) = “not independent”
Conditional independences

\(P \not\!\perp\!\!\!\perp C\)
\(S \not\!\perp\!\!\!\perp C\)
\(S \perp\!\!\!\perp P | C\)
P is not independent of C
S is not independent of C
S is independent of P, conditional on C
Causal paths

\(P \rightarrow S\)
\(P \leftarrow C \rightarrow S\)
Causal paths

\(S \leftarrow C \rightarrow p\)
Workplace and use of prestige variable

| Path | Open | Backdoor |
|---|---|---|
| \(W \rightarrow P\) | yes | no |
| \(W \leftarrow S \rightarrow A \rightarrow E \rightarrow P\) | yes | yes |
| \(W \leftarrow S \rightarrow A \rightarrow P\) | yes | yes |
| \(W \leftarrow S \rightarrow E \rightarrow P\) | yes | yes |
| \(W \leftarrow S \rightarrow E \leftarrow A \rightarrow P\) | no | yes |
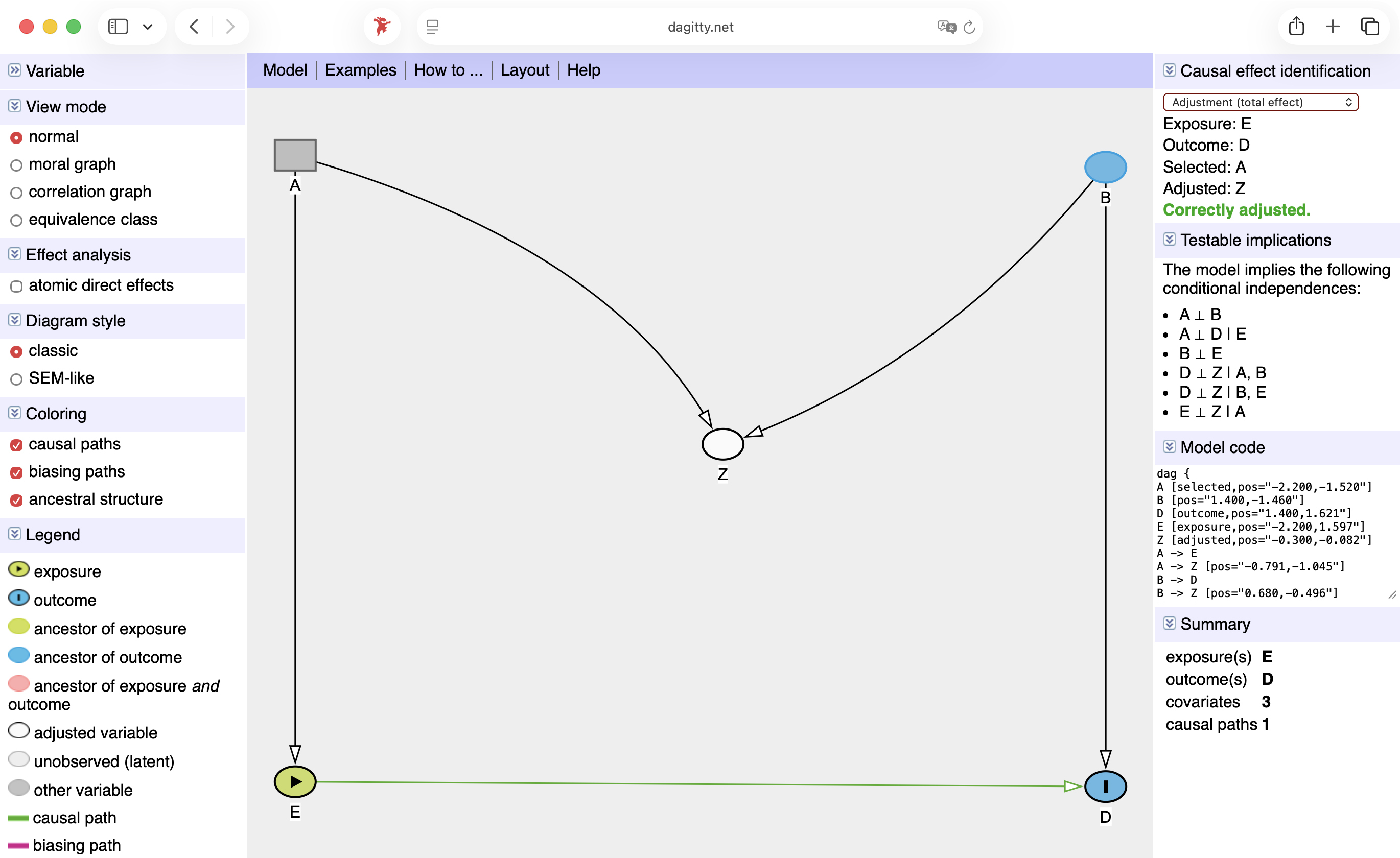
Workplace and use of prestige: adjustment sets

A, E
S
lm(P ~ W + S)
Dagitty
Limitations

It assumes DAG is correct.

Adjustment variables should be observable.

Complex systems require dynamic system modelling.
Summary
Correlation is causation (if you use causal inference).
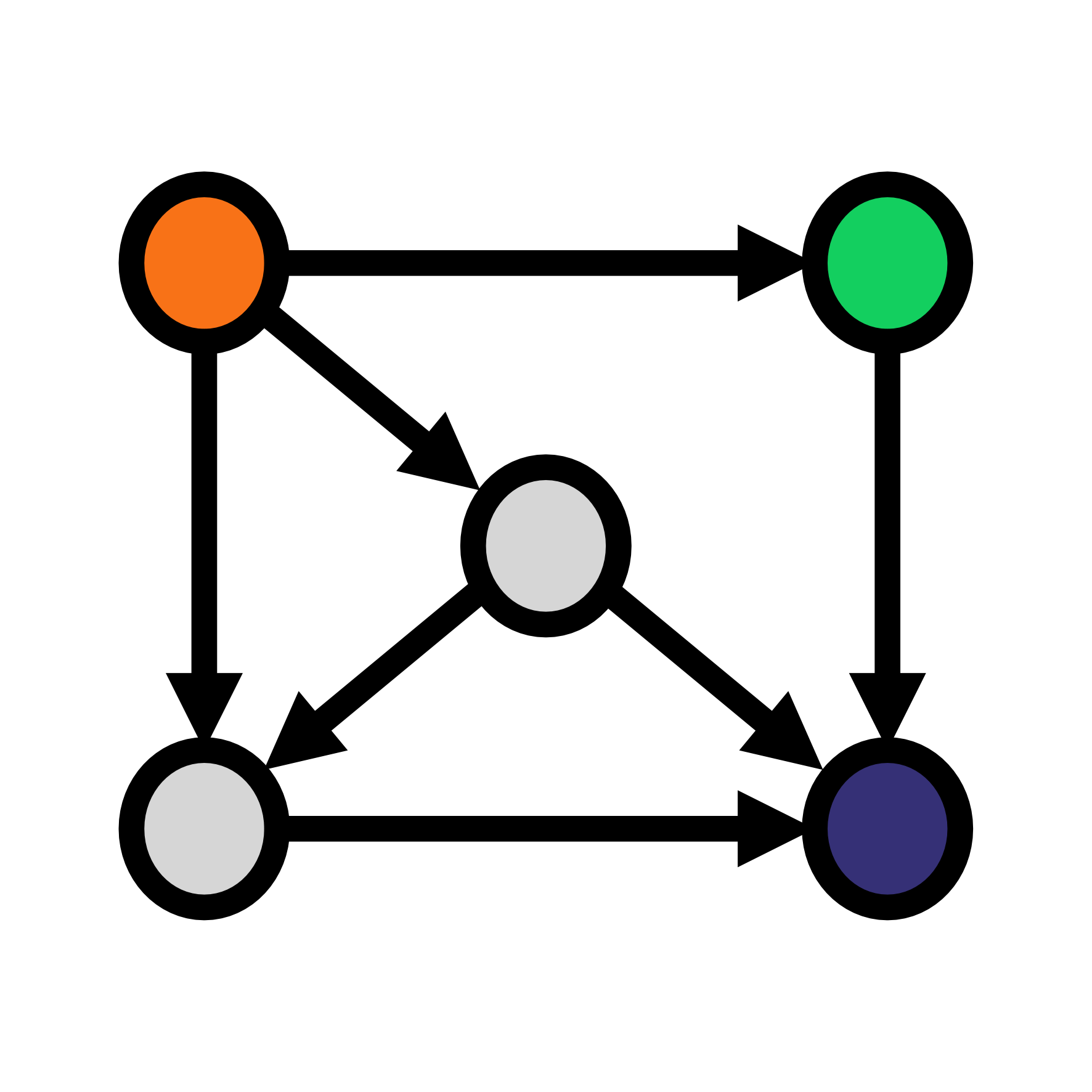
Directed Acyclic Graphs (DAGs).

Choose your covariates carefully.