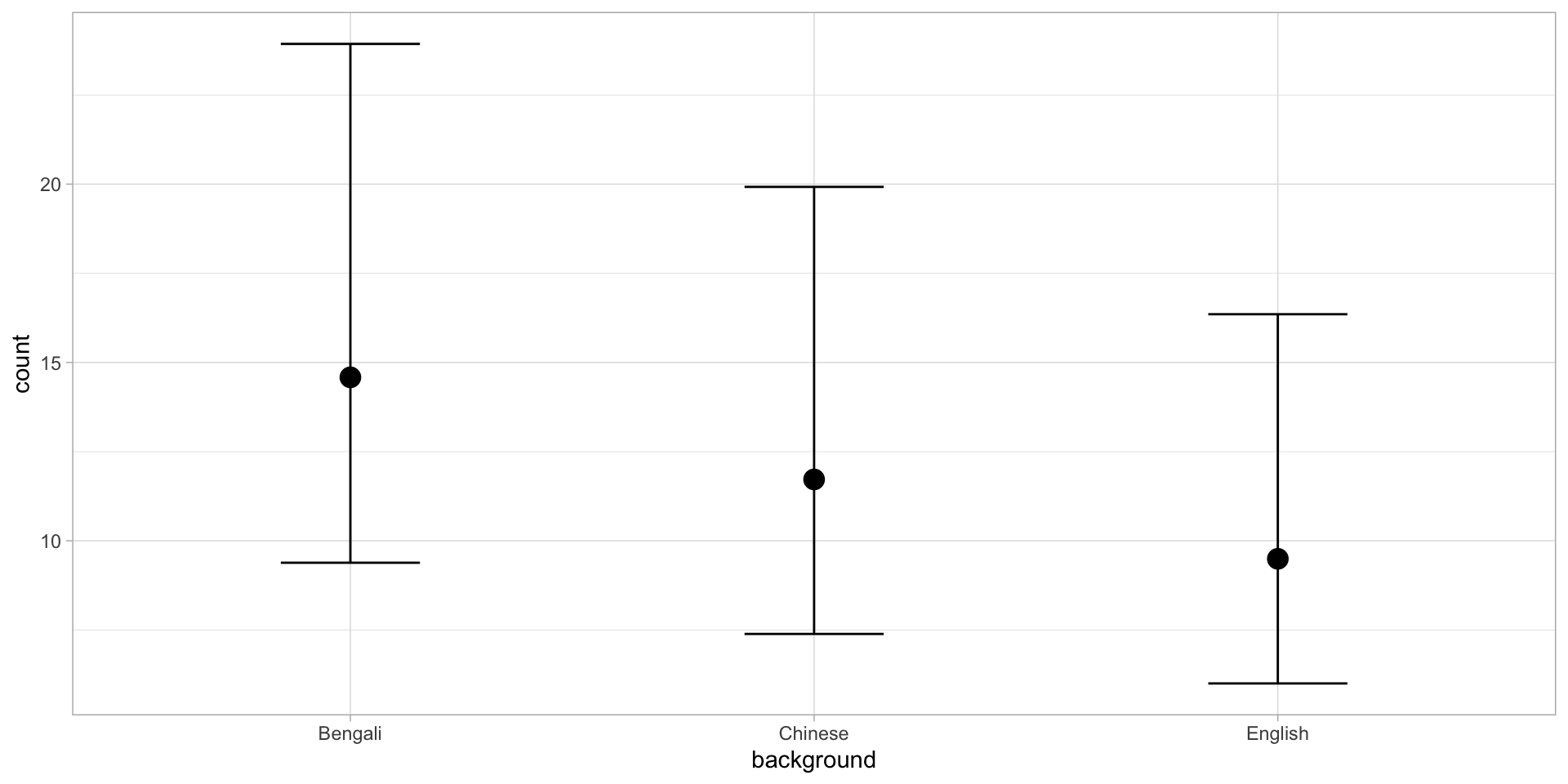
gestures <- read_csv("data/cameron2020/gestures.csv")
gestures_count <- gestures |>
filter(months == 11) |>
summarise(
count = sum(count, na.rm = TRUE),
.by = c(background, dyad)
)
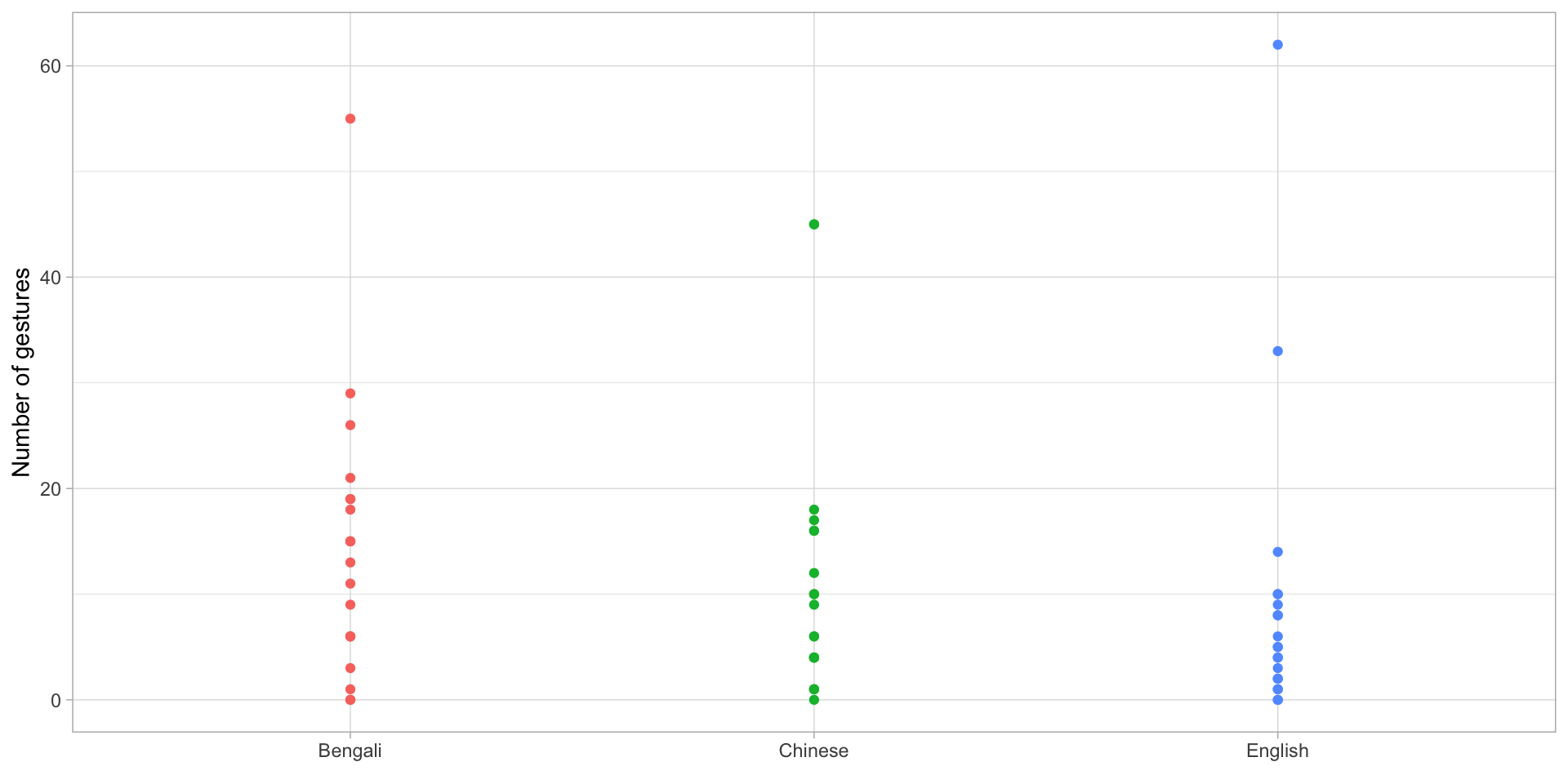
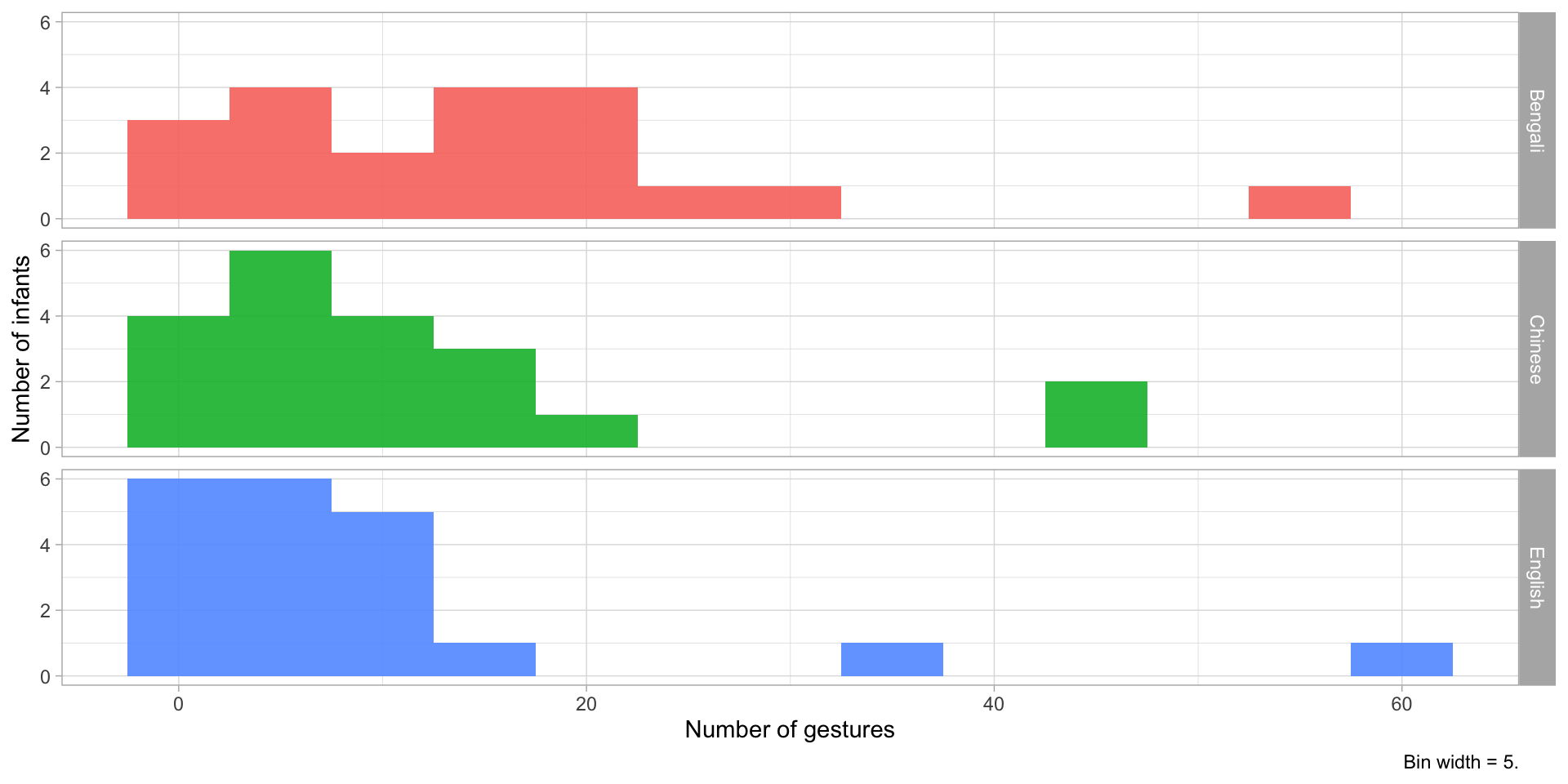
gestures_count# A tibble: 60 × 3
background dyad count
<chr> <chr> <dbl>
1 Bengali b01 9
2 Bengali b02 18
3 Bengali b03 15
4 Bengali b04 21
5 Bengali b05 13
6 Bengali b06 6
7 Bengali b07 6
8 Bengali b08 19
9 Bengali b09 6
10 Bengali b10 1
# ℹ 50 more rows